 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning-Guided Claim Normalization for Noisy Multilingual Social Media Posts
Nov 07, 2025We address claim normalization for multilingual misinformation detection - transforming noisy social media posts into clear, verifiable statements across 20 languages. The key contribution demonstrates how systematic decomposition of posts using Who, What, Where, When, Why and How questions enables robust cross-lingual transfer despite training exclusively on English data. Our methodology incorporates finetuning Qwen3-14B using LoRA with the provided dataset after intra-post deduplication, token-level recall filtering for semantic alignment and retrieval-augmented few-shot learning with contextual examples during inference. Our system achieves METEOR scores ranging from 41.16 (English) to 15.21 (Marathi), securing third rank on the English leaderboard and fourth rank for Dutch and Punjabi. The approach shows 41.3% relative improvement in METEOR over baseline configurations and substantial gains over existing methods. Results demonstrate effective cross-lingual generalization for Romance and Germanic languages while maintaining semantic coherence across diverse linguistic structures.
TIFIN India at SemEval-2025: Harnessing Translation to Overcome Multilingual IR Challenges in Fact-Checked Claim Retrieval
Apr 23, 2025We address the challenge of retrieving previously fact-checked claims in monolingual and crosslingual settings - a critical task given the global prevalence of disinformation. Our approach follows a two-stage strategy: a reliable baseline retrieval system using a fine-tuned embedding model and an LLM-based reranker. Our key contribution is demonstrating how LLM-based translation can overcome the hurdles of multilingual information retrieval. Additionally, we focus on ensuring that the bulk of the pipeline can be replicated on a consumer GPU. Our final integrated system achieved a success@10 score of 0.938 and 0.81025 on the monolingual and crosslingual test sets, respectively.
Birbal: An efficient 7B instruct-model fine-tuned with curated datasets
Mar 04, 2024LLMOps incur significant costs due to hardware requirements, hindering their widespread accessibility. Additionally, a lack of transparency in model training methods and data contributes to the majority of models being non-reproducible. To tackle these challenges, the LLM Efficiency Challenge was introduced at NeurIPS Workshop, aiming to adapt foundation models on a diverse set of tasks via fine-tuning on a single GPU (RTX 4090 or A100 with 40GB) within a 24-hour timeframe. In this system description paper, we introduce Birbal, our Mistral-7B based winning model, fine-tuned on a single RTX 4090 for 16 hours. Birbal's success lies in curating high-quality instructions covering diverse tasks, resulting in a 35% performance improvement over second-best Qwen-14B based submission.
Nearest Neighbor Search over Vectorized Lexico-Syntactic Patterns for Relation Extraction from Financial Documents
Oct 26, 2023



Relation extraction (RE) has achieved remarkable progress with the help of pre-trained language models. However, existing RE models are usually incapable of handling two situations: implicit expressions and long-tail relation classes, caused by language complexity and data sparsity. Further, these approaches and models are largely inaccessible to users who don't have direct access to large language models (LLMs) and/or infrastructure for supervised training or fine-tuning. Rule-based systems also struggle with implicit expressions. Apart from this, Real world financial documents such as various 10-X reports (including 10-K, 10-Q, etc.) of publicly traded companies pose another challenge to rule-based systems in terms of longer and complex sentences. In this paper, we introduce a simple approach that consults training relations at test time through a nearest-neighbor search over dense vectors of lexico-syntactic patterns and provides a simple yet effective means to tackle the above issues. We evaluate our approach on REFinD and show that our method achieves state-of-the-art performance. We further show that it can provide a good start for human in the loop setup when a small number of annotations are available and it is also beneficial when domain experts can provide high quality patterns.
GPT-FinRE: In-context Learning for Financial Relation Extraction using Large Language Models
Jun 30, 2023
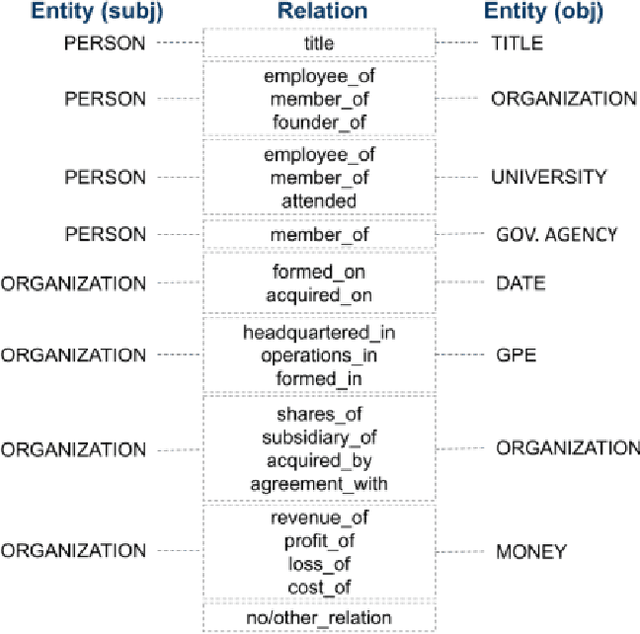
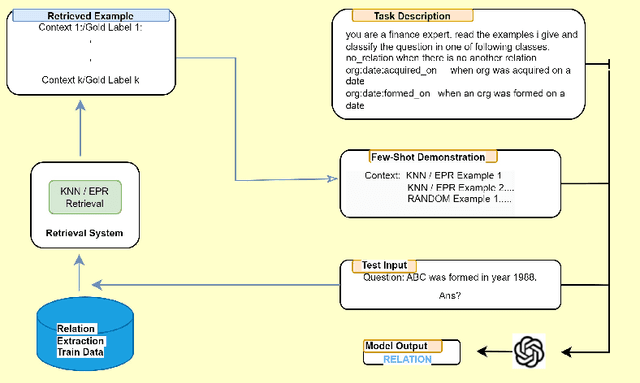
Relation extraction (RE) is a crucial task in natural language processing (NLP) that aims to identify and classify relationships between entities mentioned in text. In the financial domain, relation extraction plays a vital role in extracting valuable information from financial documents, such as news articles, earnings reports, and company filings. This paper describes our solution to relation extraction on one such dataset REFinD. The dataset was released along with shared task as a part of the Fourth Workshop on Knowledge Discovery from Unstructured Data in Financial Services, co-located with SIGIR 2023. In this paper, we employed OpenAI models under the framework of in-context learning (ICL). We utilized two retrieval strategies to find top K relevant in-context learning demonstrations / examples from training data for a given test example. The first retrieval mechanism, we employed, is a learning-free dense retriever and the other system is a learning-based retriever. We were able to achieve 4th rank on the leaderboard. Our best F1-score is 0.718.
Lexical Simplification using multi level and modular approach
Feb 03, 2023



Text Simplification is an ongoing problem in Natural Language Processing, solution to which has varied implications. In conjunction with the TSAR-2022 Workshop @EMNLP2022 Lexical Simplification is the process of reducing the lexical complexity of a text by replacing difficult words with easier to read (or understand) expressions while preserving the original information and meaning. This paper explains the work done by our team "teamPN" for English sub task. We created a modular pipeline which combines modern day transformers based models with traditional NLP methods like paraphrasing and verb sense disambiguation. We created a multi level and modular pipeline where the target text is treated according to its semantics(Part of Speech Tag). Pipeline is multi level as we utilize multiple source models to find potential candidates for replacement, It is modular as we can switch the source models and their weight-age in the final re-ranking.
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).