 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextualized Word Representations for Reading Comprehension
Sep 04, 2018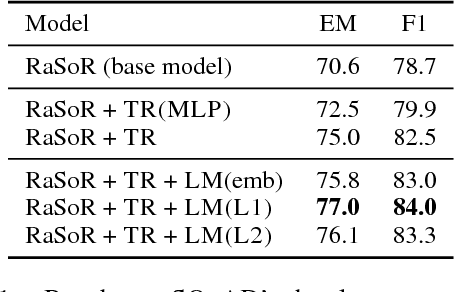
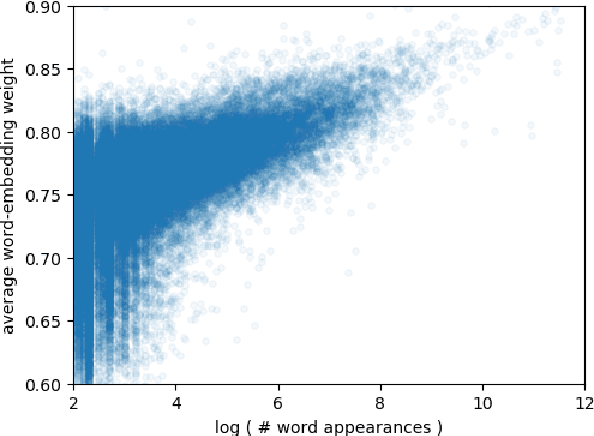
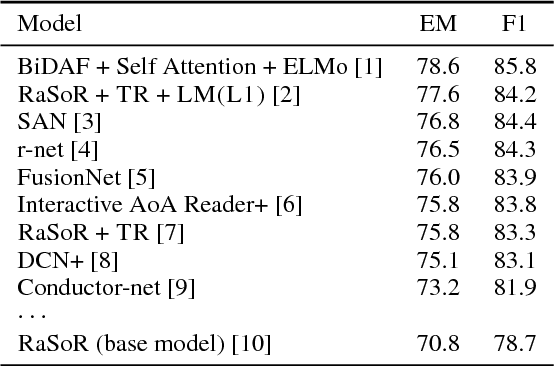
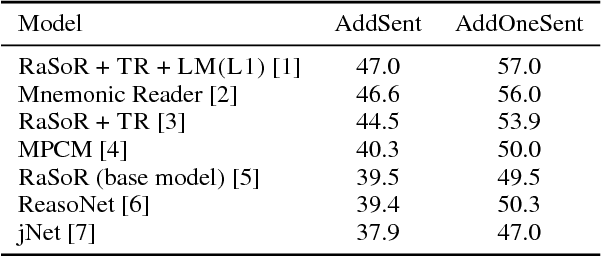
Reading a document and extracting an answer to a question about its content has attracted substantial attention recently. While most work has focused on the interaction between the question and the document, in this work we evaluate the importance of context when the question and document are processed independently. We take a standard neural architecture for this task, and show that by providing rich contextualized word representations from a large pre-trained language model as well as allowing the model to choose between context-dependent and context-independent word representations, we can obtain dramatic improvements and reach performance comparable to state-of-the-art on the competitive SQuAD dataset.
Learning Recurrent Span Representations for Extractive Question Answering
Mar 17, 2017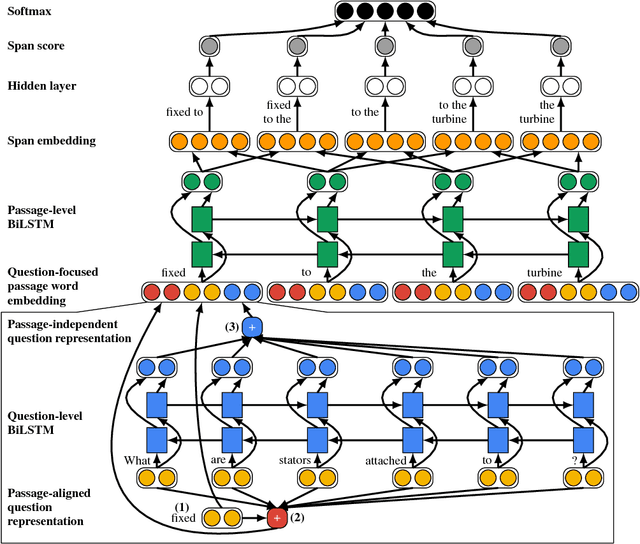
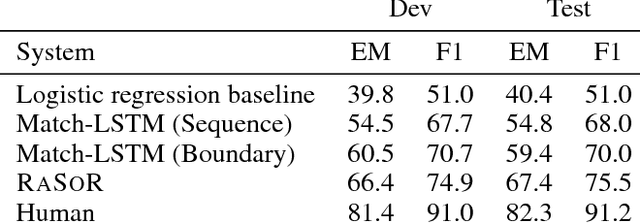

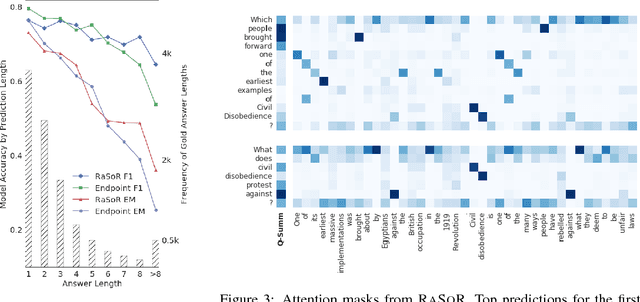
The reading comprehension task, that asks questions about a given evidence document, is a central problem in natural language understanding. Recent formulations of this task have typically focused on answer selection from a set of candidates pre-defined manually or through the use of an external NLP pipeline. However, Rajpurkar et al. (2016) recently released the SQuAD dataset in which the answers can be arbitrary strings from the supplied text. In this paper, we focus on this answer extraction task, presenting a novel model architecture that efficiently builds fixed length representations of all spans in the evidence document with a recurrent network. We show that scoring explicit span representations significantly improves performance over other approaches that factor the prediction into separate predictions about words or start and end markers. Our approach improves upon the best published results of Wang & Jiang (2016) by 5% and decreases the error of Rajpurkar et al.'s baseline by > 50%.