 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolutionary Strategies lead to Catastrophic Forgetting in LLMs
Jan 28, 2026One of the biggest missing capabilities in current AI systems is the ability to learn continuously after deployment. Implementing such continually learning systems have several challenges, one of which is the large memory requirement of gradient-based algorithms that are used to train state-of-the-art LLMs. Evolutionary Strategies (ES) have recently re-emerged as a gradient-free alternative to traditional learning algorithms and have shown encouraging performance on specific tasks in LLMs. In this paper, we perform a comprehensive analysis of ES and specifically evaluate its forgetting curves when training for an increasing number of update steps. We first find that ES is able to reach performance numbers close to GRPO for math and reasoning tasks with a comparable compute budget. However, and most importantly for continual learning, the performance gains in ES is accompanied by significant forgetting of prior abilities, limiting its applicability for training models online. We also explore the reason behind this behavior and show that the updates made using ES are much less sparse and have orders of magnitude larger $\ell_2$ norm compared to corresponding GRPO updates, explaining the contrasting forgetting curves between the two algorithms. With this study, we aim to highlight the issue of forgetting in gradient-free algorithms like ES and hope to inspire future work to mitigate these issues.
On the Sins of Image Synthesis Loss for Self-supervised Depth Estimation
Sep 13, 2021


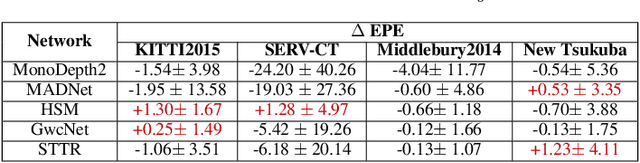
Scene depth estimation from stereo and monocular imagery is critical for extracting 3D information for downstream tasks such as scene understanding. Recently, learning-based methods for depth estimation have received much attention due to their high performance and flexibility in hardware choice. However, collecting ground truth data for supervised training of these algorithms is costly or outright impossible. This circumstance suggests a need for alternative learning approaches that do not require corresponding depth measurements. Indeed, self-supervised learning of depth estimation provides an increasingly popular alternative. It is based on the idea that observed frames can be synthesized from neighboring frames if accurate depth of the scene is known - or in this case, estimated. We show empirically that - contrary to common belief - improvements in image synthesis do not necessitate improvement in depth estimation. Rather, optimizing for image synthesis can result in diverging performance with respect to the main prediction objective - depth. We attribute this diverging phenomenon to aleatoric uncertainties, which originate from data. Based on our experiments on four datasets (spanning street, indoor, and medical) and five architectures (monocular and stereo), we conclude that this diverging phenomenon is independent of the dataset domain and not mitigated by commonly used regularization techniques. To underscore the importance of this finding, we include a survey of methods which use image synthesis, totaling 127 papers over the last six years. This observed divergence has not been previously reported or studied in depth, suggesting room for future improvement of self-supervised approaches which might be impacted the finding.