 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Reality for Synergistic Surgical Training and Data Generation
Nov 15, 2021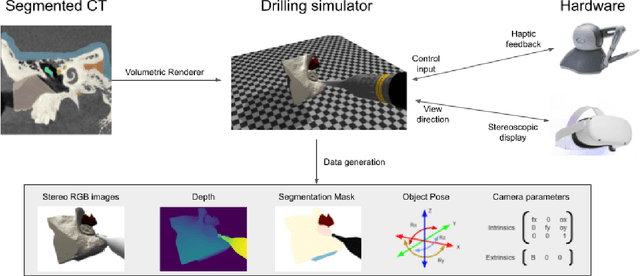
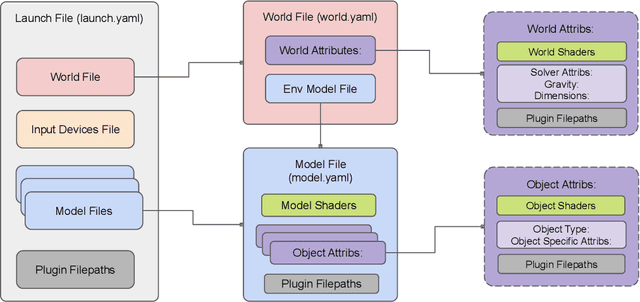
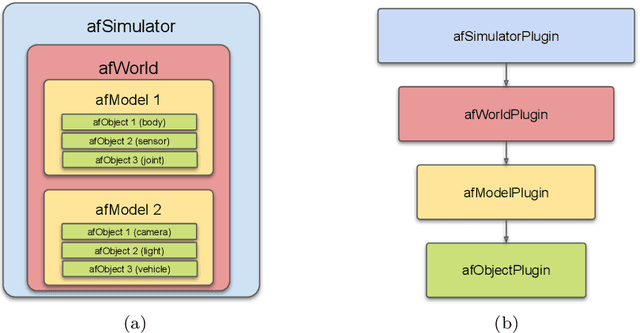
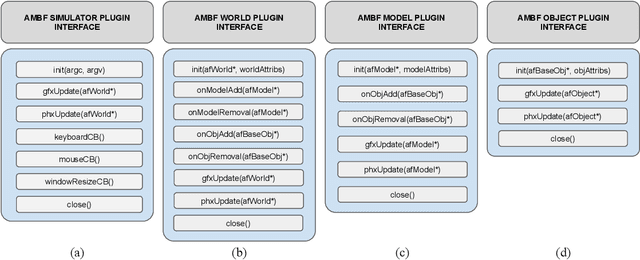
Surgical simulators not only allow planning and training of complex procedures, but also offer the ability to generate structured data for algorithm development, which may be applied in image-guided computer assisted interventions. While there have been efforts on either developing training platforms for surgeons or data generation engines, these two features, to our knowledge, have not been offered together. We present our developments of a cost-effective and synergistic framework, named Asynchronous Multibody Framework Plus (AMBF+), which generates data for downstream algorithm development simultaneously with users practicing their surgical skills. AMBF+ offers stereoscopic display on a virtual reality (VR) device and haptic feedback for immersive surgical simulation. It can also generate diverse data such as object poses and segmentation maps. AMBF+ is designed with a flexible plugin setup which allows for unobtrusive extension for simulation of different surgical procedures. We show one use case of AMBF+ as a virtual drilling simulator for lateral skull-base surgery, where users can actively modify the patient anatomy using a virtual surgical drill. We further demonstrate how the data generated can be used for validating and training downstream computer vision algorithms
On the Sins of Image Synthesis Loss for Self-supervised Depth Estimation
Sep 13, 2021


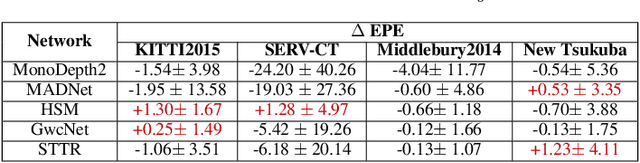
Scene depth estimation from stereo and monocular imagery is critical for extracting 3D information for downstream tasks such as scene understanding. Recently, learning-based methods for depth estimation have received much attention due to their high performance and flexibility in hardware choice. However, collecting ground truth data for supervised training of these algorithms is costly or outright impossible. This circumstance suggests a need for alternative learning approaches that do not require corresponding depth measurements. Indeed, self-supervised learning of depth estimation provides an increasingly popular alternative. It is based on the idea that observed frames can be synthesized from neighboring frames if accurate depth of the scene is known - or in this case, estimated. We show empirically that - contrary to common belief - improvements in image synthesis do not necessitate improvement in depth estimation. Rather, optimizing for image synthesis can result in diverging performance with respect to the main prediction objective - depth. We attribute this diverging phenomenon to aleatoric uncertainties, which originate from data. Based on our experiments on four datasets (spanning street, indoor, and medical) and five architectures (monocular and stereo), we conclude that this diverging phenomenon is independent of the dataset domain and not mitigated by commonly used regularization techniques. To underscore the importance of this finding, we include a survey of methods which use image synthesis, totaling 127 papers over the last six years. This observed divergence has not been previously reported or studied in depth, suggesting room for future improvement of self-supervised approaches which might be impacted the finding.