 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Discriminative Domain Alignment for Unsupervised Domain Adaptation
Sep 26, 2019
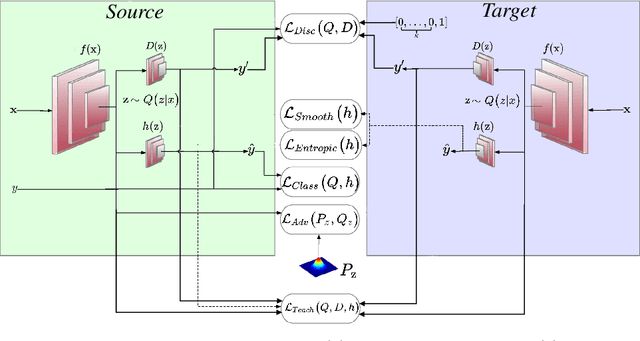

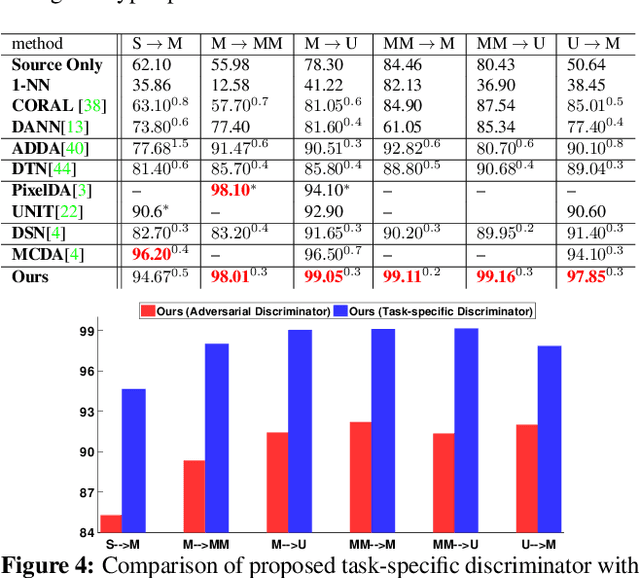
Domain Adaptation (DA), the process of effectively adapting task models learned on one domain, the source, to other related but distinct domains, the targets, with no or minimal retraining, is typically accomplished using the process of source-to-target manifold alignment. However, this process often leads to unsatisfactory adaptation performance, in part because it ignores the task-specific structure of the data. In this paper, we improve the performance of DA by introducing a discriminative discrepancy measure which takes advantage of auxiliary information available in the source and the target domains to better align the source and target distributions. Specifically, we leverage the cohesive clustering structure within individual data manifolds, associated with different tasks, to improve the alignment. This structure is explicit in the source, where the task labels are available, but is implicit in the target, making the problem challenging. We address the challenge by devising a deep DA framework, which combines a new task-driven domain alignment discriminator with domain regularizers that encourage the shared features as task-specific and domain invariant, and prompt the task model to be data structure preserving, guiding its decision boundaries through the low density data regions. We validate our framework on standard benchmarks, including Digits (MNIST, USPS, SVHN, MNIST-M), PACS, and VisDA. Our results show that our proposed model consistently outperforms the state-of-the-art in unsupervised domain adaptation.
Unsupervised Visual Domain Adaptation: A Deep Max-Margin Gaussian Process Approach
Feb 23, 2019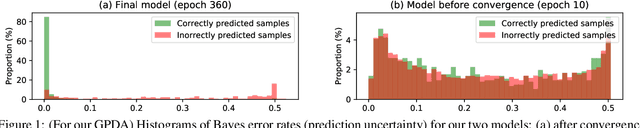

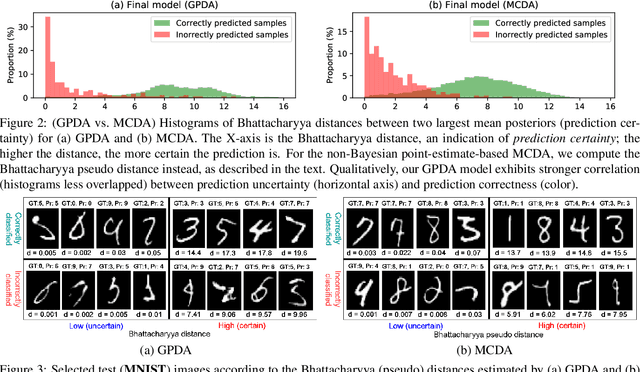
In unsupervised domain adaptation, it is widely known that the target domain error can be provably reduced by having a shared input representation that makes the source and target domains indistinguishable from each other. Very recently it has been studied that not just matching the marginal input distributions, but the alignment of output (class) distributions is also critical. The latter can be achieved by minimizing the maximum discrepancy of predictors (classifiers). In this paper, we adopt this principle, but propose a more systematic and effective way to achieve hypothesis consistency via Gaussian processes (GP). The GP allows us to define/induce a hypothesis space of the classifiers from the posterior distribution of the latent random functions, turning the learning into a simple large-margin posterior separation problem, far easier to solve than previous approaches based on adversarial minimax optimization. We formulate a learning objective that effectively pushes the posterior to minimize the maximum discrepancy. This is further shown to be equivalent to maximizing margins and minimizing uncertainty of the class predictions in the target domain, a well-established principle in classical (semi-)supervised learning. Empirical results demonstrate that our approach is comparable or superior to the existing methods on several benchmark domain adaptation datasets.
Unsupervised Multi-Target Domain Adaptation: An Information Theoretic Approach
Oct 26, 2018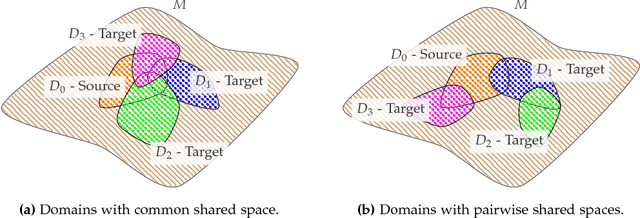
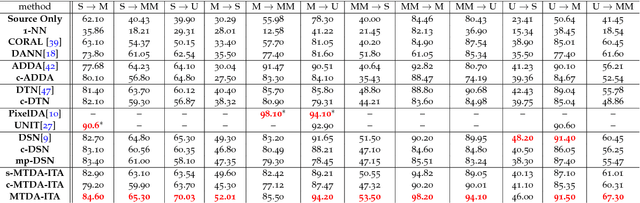
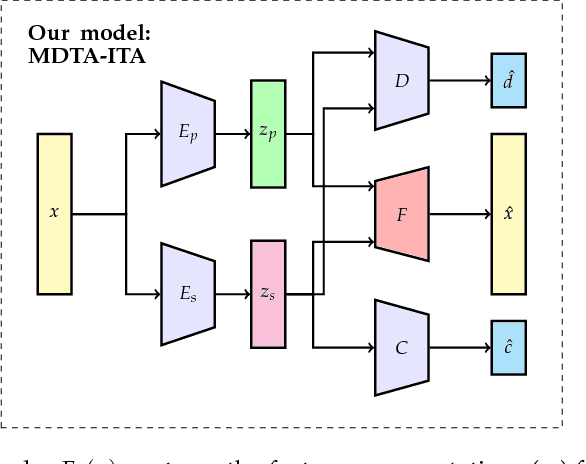

Unsupervised domain adaptation (uDA) models focus on pairwise adaptation settings where there is a single, labeled, source and a single target domain. However, in many real-world settings one seeks to adapt to multiple, but somewhat similar, target domains. Applying pairwise adaptation approaches to this setting may be suboptimal, as they fail to leverage shared information among multiple domains. In this work we propose an information theoretic approach for domain adaptation in the novel context of multiple target domains with unlabeled instances and one source domain with labeled instances. Our model aims to find a shared latent space common to all domains, while simultaneously accounting for the remaining private, domain-specific factors. Disentanglement of shared and private information is accomplished using a unified information-theoretic approach, which also serves to establish a stronger link between the latent representations and the observed data. The resulting model, accompanied by an efficient optimization algorithm, allows simultaneous adaptation from a single source to multiple target domains. We test our approach on three challenging publicly-available datasets, showing that it outperforms several popular domain adaptation methods.