 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour Context Is Not an Array: Unveiling Random Access Limitations in Transformers
Aug 10, 2024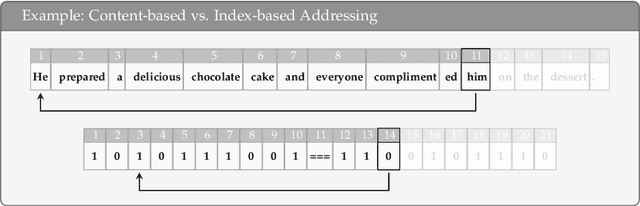



Despite their recent successes, Transformer-based large language models show surprising failure modes. A well-known example of such failure modes is their inability to length-generalize: solving problem instances at inference time that are longer than those seen during training. In this work, we further explore the root cause of this failure by performing a detailed analysis of model behaviors on the simple parity task. Our analysis suggests that length generalization failures are intricately related to a model's inability to perform random memory accesses within its context window. We present supporting evidence for this hypothesis by demonstrating the effectiveness of methodologies that circumvent the need for indexing or that enable random token access indirectly, through content-based addressing. We further show where and how the failure to perform random memory access manifests through attention map visualizations.
Sequential Gradient Coding For Straggler Mitigation
Nov 24, 2022In distributed computing, slower nodes (stragglers) usually become a bottleneck. Gradient Coding (GC), introduced by Tandon et al., is an efficient technique that uses principles of error-correcting codes to distribute gradient computation in the presence of stragglers. In this paper, we consider the distributed computation of a sequence of gradients $\{g(1),g(2),\ldots,g(J)\}$, where processing of each gradient $g(t)$ starts in round-$t$ and finishes by round-$(t+T)$. Here $T\geq 0$ denotes a delay parameter. For the GC scheme, coding is only across computing nodes and this results in a solution where $T=0$. On the other hand, having $T>0$ allows for designing schemes which exploit the temporal dimension as well. In this work, we propose two schemes that demonstrate improved performance compared to GC. Our first scheme combines GC with selective repetition of previously unfinished tasks and achieves improved straggler mitigation. In our second scheme, which constitutes our main contribution, we apply GC to a subset of the tasks and repetition for the remainder of the tasks. We then multiplex these two classes of tasks across workers and rounds in an adaptive manner, based on past straggler patterns. Using theoretical analysis, we demonstrate that our second scheme achieves significant reduction in the computational load. In our experiments, we study a practical setting of concurrently training multiple neural networks over an AWS Lambda cluster involving 256 worker nodes, where our framework naturally applies. We demonstrate that the latter scheme can yield a 16\% improvement in runtime over the baseline GC scheme, in the presence of naturally occurring, non-simulated stragglers.
Time-Resolved fMRI Shared Response Model using Gaussian Process Factor Analysis
Jun 10, 2020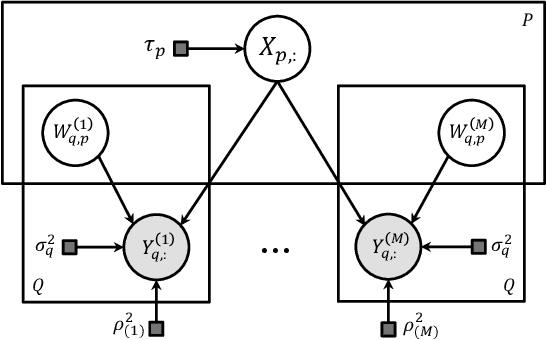
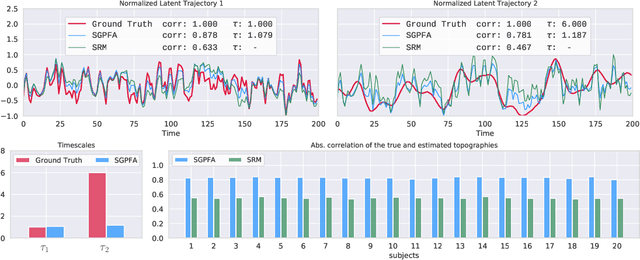
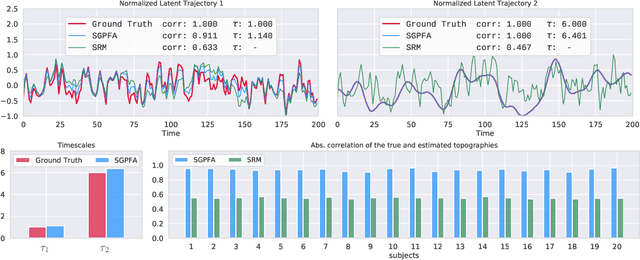
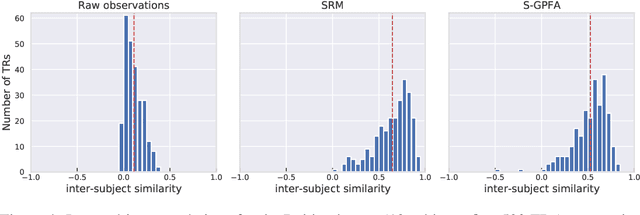
Multi-subject fMRI studies are challenging due to the high variability of both brain anatomy and functional brain topographies across participants. An effective way of aggregating multi-subject fMRI data is to extract a shared representation that filters out unwanted variability among subjects. Some recent work has implemented probabilistic models to extract a shared representation in task fMRI. In the present work, we improve upon these models by incorporating temporal information in the common latent structures. We introduce a new model, Shared Gaussian Process Factor Analysis (S-GPFA), that discovers shared latent trajectories and subject-specific functional topographies, while modelling temporal correlation in fMRI data. We demonstrate the efficacy of our model in revealing ground truth latent structures using simulated data, and replicate experimental performance of time-segment matching and inter-subject similarity on the publicly available Raider dataset. We further test the utility of our model by analyzing its learned model parameters in the large multi-site SPINS dataset, on a social cognition task from participants with and without schizophrenia.