 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Temporal Feature Enhanced Transformer with ROI-rank Based Masking for Diagnosis of ADHD
Apr 12, 2025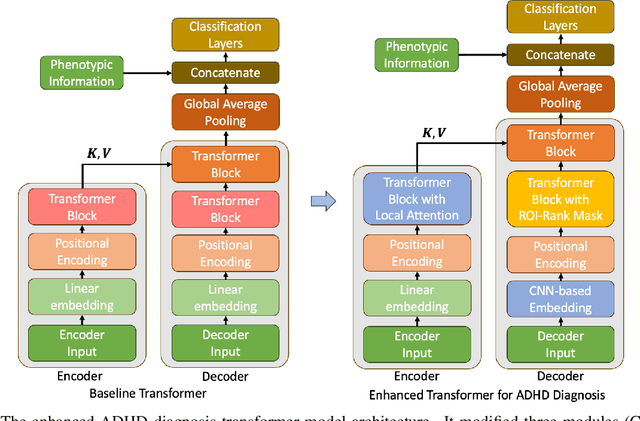



In modern society, Attention-Deficit/Hyperactivity Disorder (ADHD) is one of the common mental diseases discovered not only in children but also in adults. In this context, we propose a ADHD diagnosis transformer model that can effectively simultaneously find important brain spatiotemporal biomarkers from resting-state functional magnetic resonance (rs-fMRI). This model not only learns spatiotemporal individual features but also learns the correlation with full attention structures specialized in ADHD diagnosis. In particular, it focuses on learning local blood oxygenation level dependent (BOLD) signals and distinguishing important regions of interest (ROI) in the brain. Specifically, the three proposed methods for ADHD diagnosis transformer are as follows. First, we design a CNN-based embedding block to obtain more expressive embedding features in brain region attention. It is reconstructed based on the previously CNN-based ADHD diagnosis models for the transformer. Next, for individual spatiotemporal feature attention, we change the attention method to local temporal attention and ROI-rank based masking. For the temporal features of fMRI, the local temporal attention enables to learn local BOLD signal features with only simple window masking. For the spatial feature of fMRI, ROI-rank based masking can distinguish ROIs with high correlation in ROI relationships based on attention scores, thereby providing a more specific biomarker for ADHD diagnosis. The experiment was conducted with various types of transformer models. To evaluate these models, we collected the data from 939 individuals from all sites provided by the ADHD-200 competition. Through this, the spatiotemporal enhanced transformer for ADHD diagnosis outperforms the performance of other different types of transformer variants. (77.78ACC 76.60SPE 79.22SEN 79.30AUC)
Searching for Effective Preprocessing Method and CNN-based Architecture with Efficient Channel Attention on Speech Emotion Recognition
Sep 06, 2024Speech emotion recognition (SER) classifies human emotions in speech with a computer model. Recently, performance in SER has steadily increased as deep learning techniques have adapted. However, unlike many domains that use speech data, data for training in the SER model is insufficient. This causes overfitting of training of the neural network, resulting in performance degradation. In fact, successful emotion recognition requires an effective preprocessing method and a model structure that efficiently uses the number of weight parameters. In this study, we propose using eight dataset versions with different frequency-time resolutions to search for an effective emotional speech preprocessing method. We propose a 6-layer convolutional neural network (CNN) model with efficient channel attention (ECA) to pursue an efficient model structure. In particular, the well-positioned ECA blocks can improve channel feature representation with only a few parameters. With the interactive emotional dyadic motion capture (IEMOCAP) dataset, increasing the frequency resolution in preprocessing emotional speech can improve emotion recognition performance. Also, ECA after the deep convolution layer can effectively increase channel feature representation. Consequently, the best result (79.37UA 79.68WA) can be obtained, exceeding the performance of previous SER models. Furthermore, to compensate for the lack of emotional speech data, we experiment with multiple preprocessing data methods that augment trainable data preprocessed with all different settings from one sample. In the experiment, we can achieve the highest result (80.28UA 80.46WA).
Finding essential parts of the brain in rs-fMRI can improve diagnosing ADHD by Deep Learning
Aug 14, 2021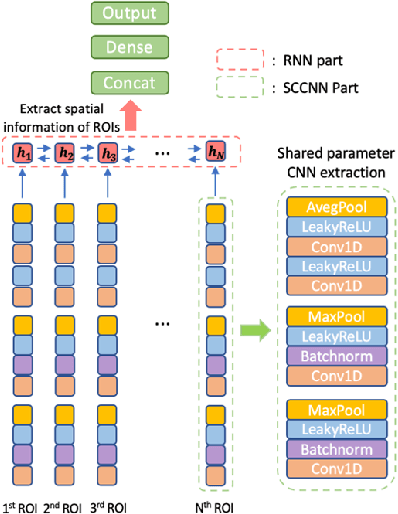

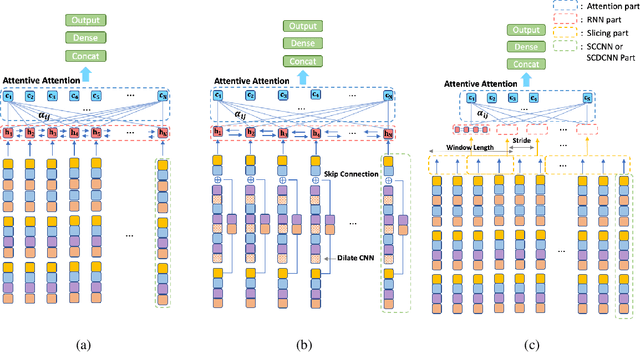

Attention Deficit\Hyperactivity Disorder(ADHD) is considered a very common psychiatric disorder, but it is difficult to establish an accurate diagnostic method for ADHD. Recently, with the development of computing resources and machine learning methods, studies have been conducted to classify ADHD using resting-state functional magnetic resonance(rsfMRI) imaging data. However, most of them utilized all areas of the brain for training the models. In this study, as a different way from this approach, we conducted a study to classify ADHD by selecting areas that are essential for using a deep learning model. For the experiment, rsfMRI data provided by ADHD 200 global competition was used. To obtain an integrated result from the multiple sites, each region of the brain was evaluated with Leave one site out cross-validation. As a result, when we only used 15 important region of interest(ROIs) for training, an accuracy of 70.6% was obtained, significantly exceeding the existing results of 68.6% from all ROIs. In addition, to explore the new structure based on SCCNN-RNN, we performed the same experiment with three modified models: (1) Separate Channel CNN RNN with Attention (ASCRNN), (2) Separate Channel dilate CNN RNN with Attention (ASDRNN), (3) Separate Channel CNN slicing RNN with Attention (ASSRNN). As a result, the ASSRNN model provided a high accuracy of 70.46% when training with only 13 important region of interest (ROI). These results show that finding and using the crucial parts of the brain in diagnosing ADHD by Deep Learning can get better results than using all areas.