 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuse & Calibrate: A bi-directional Vision-Language Guided Framework for Referring Image Segmentation
May 18, 2024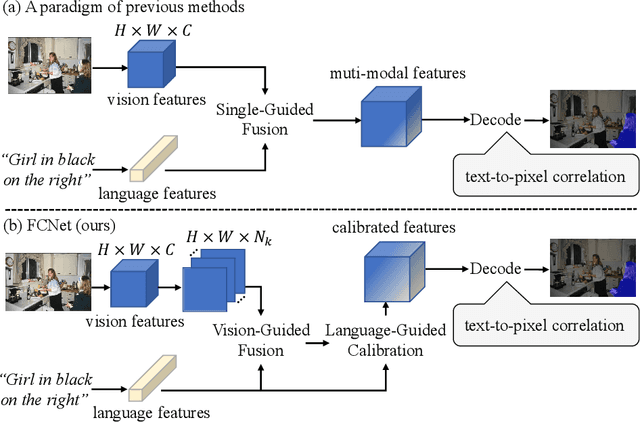
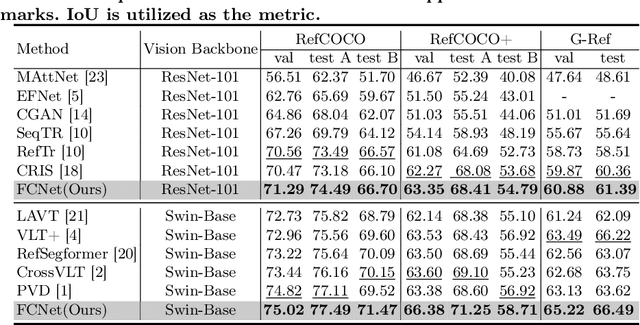
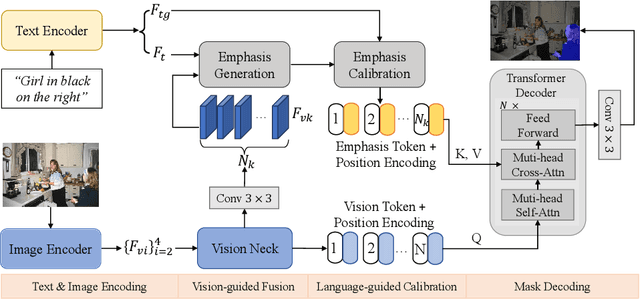
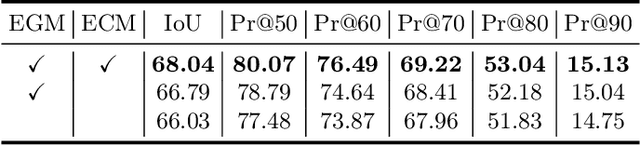
Referring Image Segmentation (RIS) aims to segment an object described in natural language from an image, with the main challenge being a text-to-pixel correlation. Previous methods typically rely on single-modality features, such as vision or language features, to guide the multi-modal fusion process. However, this approach limits the interaction between vision and language, leading to a lack of fine-grained correlation between the language description and pixel-level details during the decoding process. In this paper, we introduce FCNet, a framework that employs a bi-directional guided fusion approach where both vision and language play guiding roles. Specifically, we use a vision-guided approach to conduct initial multi-modal fusion, obtaining multi-modal features that focus on key vision information. We then propose a language-guided calibration module to further calibrate these multi-modal features, ensuring they understand the context of the input sentence. This bi-directional vision-language guided approach produces higher-quality multi-modal features sent to the decoder, facilitating adaptive propagation of fine-grained semantic information from textual features to visual features. Experiments on RefCOCO, RefCOCO+, and G-Ref datasets with various backbones consistently show our approach outperforming state-of-the-art methods.
Boreas: A Multi-Season Autonomous Driving Dataset
Mar 18, 2022
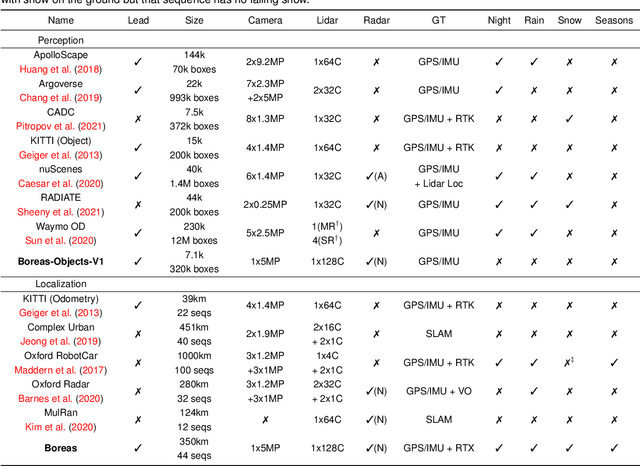


The Boreas dataset was collected by driving a repeated route over the course of one year, resulting in stark seasonal variations and adverse weather conditions such as rain and falling snow. In total, the Boreas dataset contains over 350km of driving data featuring a 128-channel Velodyne Alpha-Prime lidar, a 360 degree Navtech CIR304-H scanning radar, a 5MP FLIR Blackfly S camera, and centimetre-accurate post-processed ground truth poses. At launch, our dataset will support live leaderboards for odometry, metric localization, and 3D object detection. The dataset and development kit are available at: https://www.boreas.utias.utoronto.ca
Zeus: A System Description of the Two-Time Winner of the Collegiate SAE AutoDrive Competition
Apr 19, 2020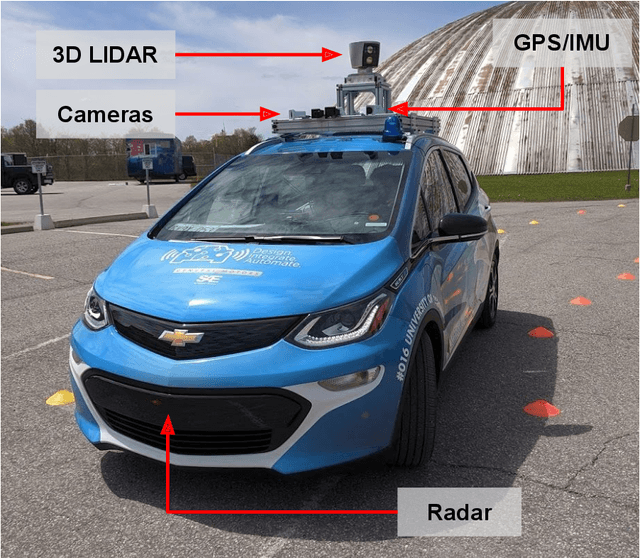


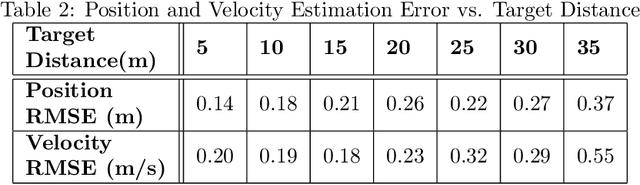
The SAE AutoDrive Challenge is a three-year collegiate competition to develop a self-driving car by 2020. The second year of the competition was held in June 2019 at MCity, a mock town built for self-driving car testing at the University of Michigan. Teams were required to autonomously navigate a series of intersections while handling pedestrians, traffic lights, and traffic signs. Zeus is aUToronto's winning entry in the AutoDrive Challenge. This article describes the system design and development of Zeus as well as many of the lessons learned along the way. This includes details on the team's organizational structure, sensor suite, software components, and performance at the Year 2 competition. With a team of mostly undergraduates and minimal resources, aUToronto has made progress towards a functioning self-driving vehicle, in just two years. This article may prove valuable to researchers looking to develop their own self-driving platform.
Normalized and Geometry-Aware Self-Attention Network for Image Captioning
Mar 19, 2020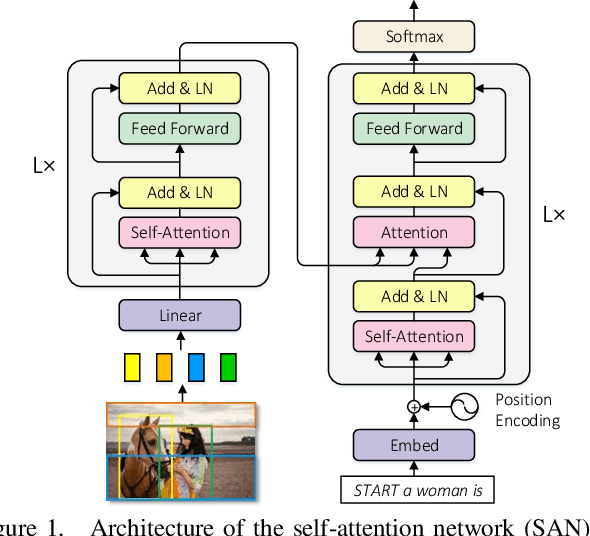
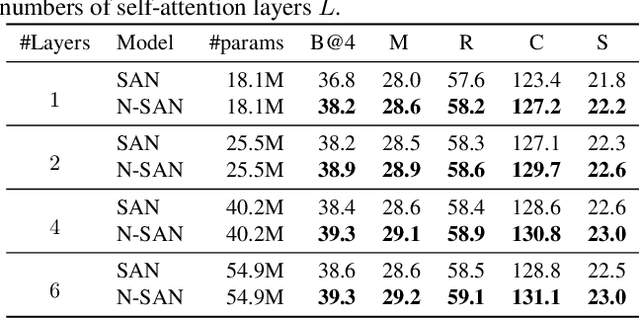
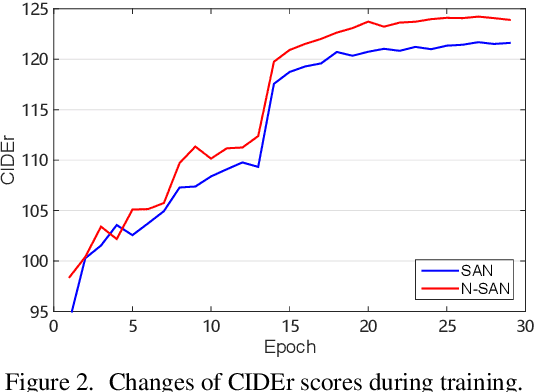
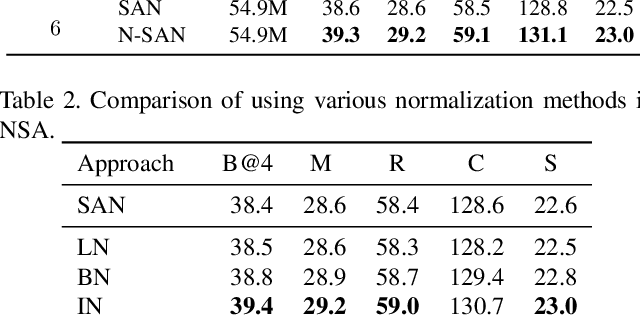
Self-attention (SA) network has shown profound value in image captioning. In this paper, we improve SA from two aspects to promote the performance of image captioning. First, we propose Normalized Self-Attention (NSA), a reparameterization of SA that brings the benefits of normalization inside SA. While normalization is previously only applied outside SA, we introduce a novel normalization method and demonstrate that it is both possible and beneficial to perform it on the hidden activations inside SA. Second, to compensate for the major limit of Transformer that it fails to model the geometry structure of the input objects, we propose a class of Geometry-aware Self-Attention (GSA) that extends SA to explicitly and efficiently consider the relative geometry relations between the objects in the image. To construct our image captioning model, we combine the two modules and apply it to the vanilla self-attention network. We extensively evaluate our proposals on MS-COCO image captioning dataset and superior results are achieved when comparing to state-of-the-art approaches. Further experiments on three challenging tasks, i.e. video captioning, machine translation, and visual question answering, show the generality of our methods.
Multi-View Features and Hybrid Reward Strategies for Vatex Video Captioning Challenge 2019
Oct 31, 2019
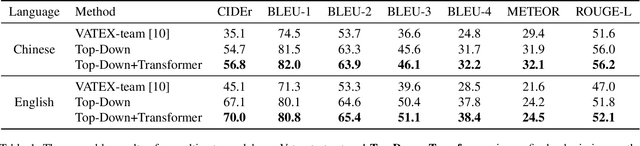
This document describes our solution for the VATEX Captioning Challenge 2019, which requires generating descriptions for the videos in both English and Chinese languages. We identified three crucial factors that improve the performance, namely: multi-view features, hybrid reward, and diverse ensemble. Our method achieves the 2nd and the 3rd places on the Chinese and English video captioning tracks, respectively.