 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Role of LLMs in Multimodal Evaluation Benchmarks
Paper and Code
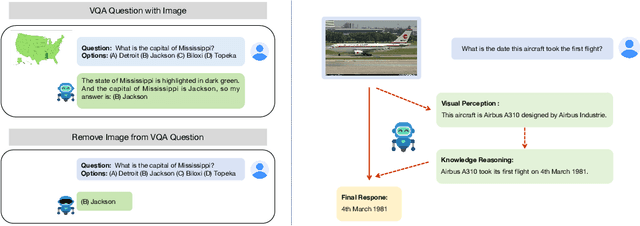
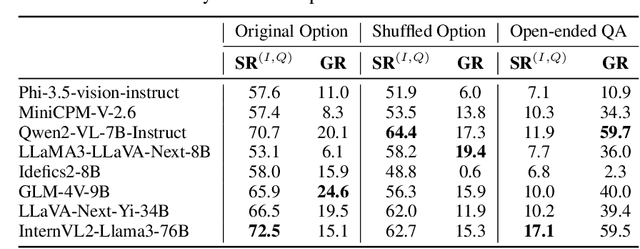
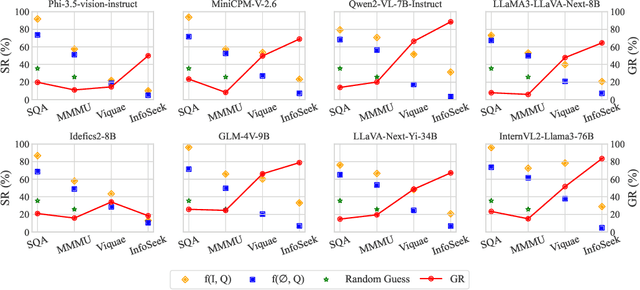
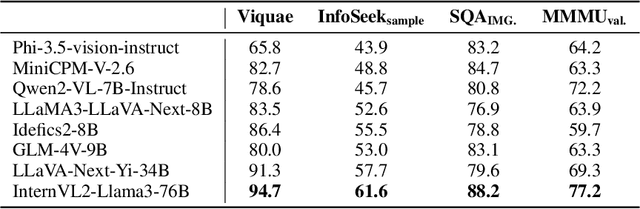
The rapid advancement of Multimodal Large Language Models (MLLMs) has been accompanied by the development of various benchmarks to evaluate their capabilities. However, the true nature of these evaluations and the extent to which they assess multimodal reasoning versus merely leveraging the underlying Large Language Model (LLM) backbone remain unclear. This paper presents a comprehensive investigation into the role of LLM backbones in MLLM evaluation, focusing on two critical aspects: the degree to which current benchmarks truly assess multimodal reasoning and the influence of LLM prior knowledge on performance. Specifically, we introduce a modified evaluation protocol to disentangle the contributions of the LLM backbone from multimodal integration, and an automatic knowledge identification technique for diagnosing whether LLMs equip the necessary knowledge for corresponding multimodal questions. Our study encompasses four diverse MLLM benchmarks and eight state-of-the-art MLLMs. Key findings reveal that some benchmarks allow high performance even without visual inputs and up to 50\% of error rates can be attributed to insufficient world knowledge in the LLM backbone, indicating a heavy reliance on language capabilities. To address knowledge deficiencies, we propose a knowledge augmentation pipeline that achieves significant performance gains, with improvements of up to 60\% on certain datasets, resulting in a approximately 4x increase in performance. Our work provides crucial insights into the role of the LLM backbone in MLLMs, and highlights the need for more nuanced benchmarking approaches.