 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagFace: A Universal Representation for Face Recognition and Quality Assessment
Apr 03, 2021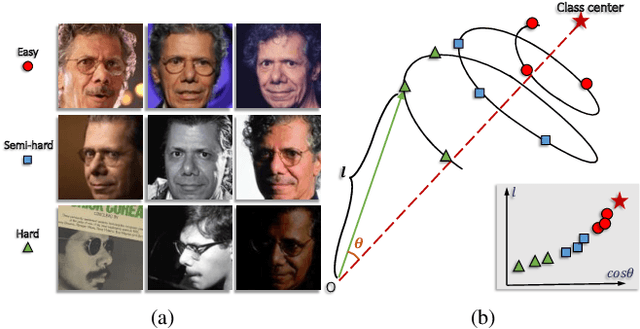



The performance of face recognition system degrades when the variability of the acquired faces increases. Prior work alleviates this issue by either monitoring the face quality in pre-processing or predicting the data uncertainty along with the face feature. This paper proposes MagFace, a category of losses that learn a universal feature embedding whose magnitude can measure the quality of the given face. Under the new loss, it can be proven that the magnitude of the feature embedding monotonically increases if the subject is more likely to be recognized. In addition, MagFace introduces an adaptive mechanism to learn a wellstructured within-class feature distributions by pulling easy samples to class centers while pushing hard samples away. This prevents models from overfitting on noisy low-quality samples and improves face recognition in the wild. Extensive experiments conducted on face recognition, quality assessments as well as clustering demonstrate its superiority over state-of-the-arts. The code is available at https://github.com/IrvingMeng/MagFace.
* accepted at CVPR 2021, Oral
Pooling the Convolutional Layers in Deep ConvNets for Action Recognition
Nov 06, 2015

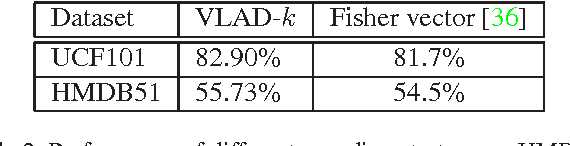
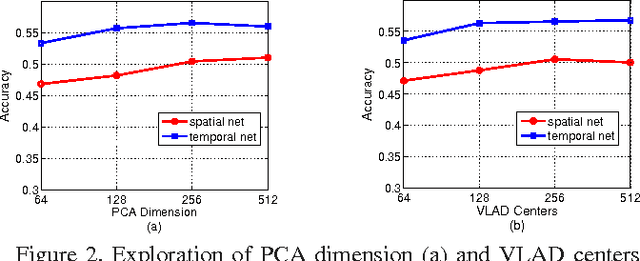
Deep ConvNets have shown its good performance in image classification tasks. However it still remains as a problem in deep video representation for action recognition. The problem comes from two aspects: on one hand, current video ConvNets are relatively shallow compared with image ConvNets, which limits its capability of capturing the complex video action information; on the other hand, temporal information of videos is not properly utilized to pool and encode the video sequences. Towards these issues, in this paper, we utilize two state-of-the-art ConvNets, i.e., the very deep spatial net (VGGNet) and the temporal net from Two-Stream ConvNets, for action representation. The convolutional layers and the proposed new layer, called frame-diff layer, are extracted and pooled with two temporal pooling strategy: Trajectory pooling and line pooling. The pooled local descriptors are then encoded with VLAD to form the video representations. In order to verify the effectiveness of the proposed framework, we conduct experiments on UCF101 and HMDB51 datasets. It achieves the accuracy of 93.78\% on UCF101 which is the state-of-the-art and the accuracy of 65.62\% on HMDB51 which is comparable to the state-of-the-art.