 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDLAFormer: An End-to-End Transformer For Document Layout Analysis
Paper and Code
May 20, 2024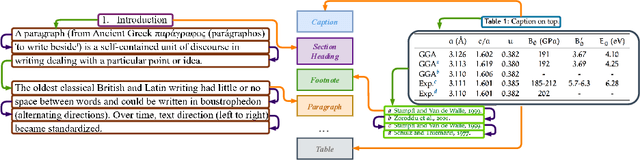
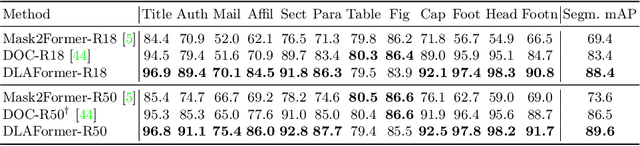
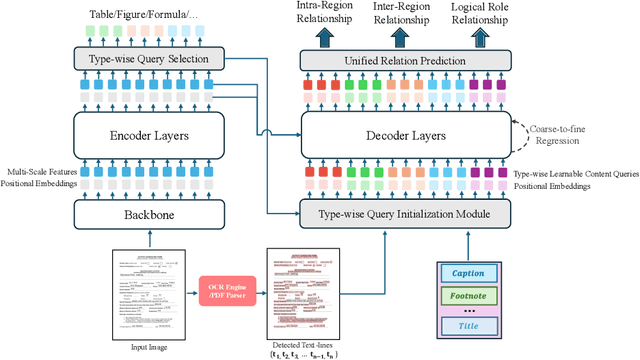

Document layout analysis (DLA) is crucial for understanding the physical layout and logical structure of documents, serving information retrieval, document summarization, knowledge extraction, etc. However, previous studies have typically used separate models to address individual sub-tasks within DLA, including table/figure detection, text region detection, logical role classification, and reading order prediction. In this work, we propose an end-to-end transformer-based approach for document layout analysis, called DLAFormer, which integrates all these sub-tasks into a single model. To achieve this, we treat various DLA sub-tasks (such as text region detection, logical role classification, and reading order prediction) as relation prediction problems and consolidate these relation prediction labels into a unified label space, allowing a unified relation prediction module to handle multiple tasks concurrently. Additionally, we introduce a novel set of type-wise queries to enhance the physical meaning of content queries in DETR. Moreover, we adopt a coarse-to-fine strategy to accurately identify graphical page objects. Experimental results demonstrate that our proposed DLAFormer outperforms previous approaches that employ multi-branch or multi-stage architectures for multiple tasks on two document layout analysis benchmarks, DocLayNet and Comp-HRDoc.