 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBA-SOT: Boundary-Aware Serialized Output Training for Multi-Talker ASR
Paper and Code
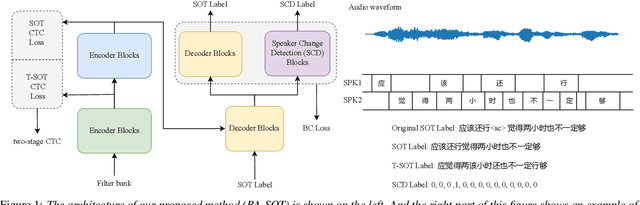
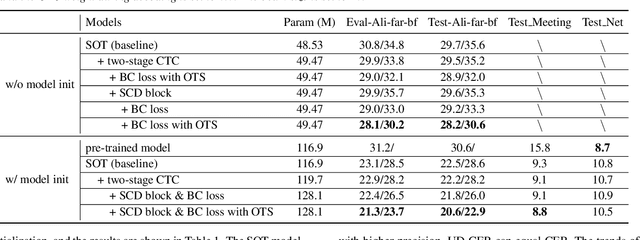
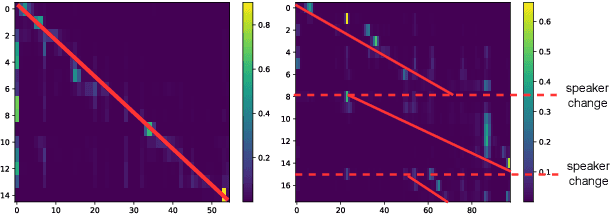
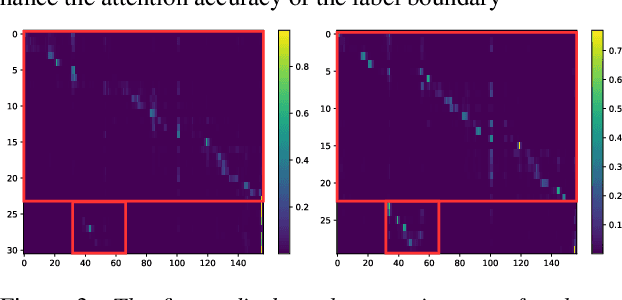
The recently proposed serialized output training (SOT) simplifies multi-talker automatic speech recognition (ASR) by generating speaker transcriptions separated by a special token. However, frequent speaker changes can make speaker change prediction difficult. To address this, we propose boundary-aware serialized output training (BA-SOT), which explicitly incorporates boundary knowledge into the decoder via a speaker change detection task and boundary constraint loss. We also introduce a two-stage connectionist temporal classification (CTC) strategy that incorporates token-level SOT CTC to restore temporal context information. Besides typical character error rate (CER), we introduce utterance-dependent character error rate (UD-CER) to further measure the precision of speaker change prediction. Compared to original SOT, BA-SOT reduces CER/UD-CER by 5.1%/14.0%, and leveraging a pre-trained ASR model for BA-SOT model initialization further reduces CER/UD-CER by 8.4%/19.9%.