 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDR-GAN: Distribution Regularization for Text-to-Image Generation
Paper and Code
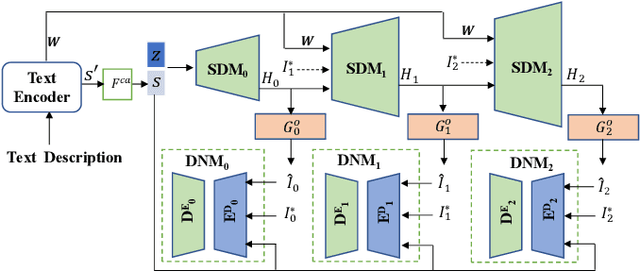
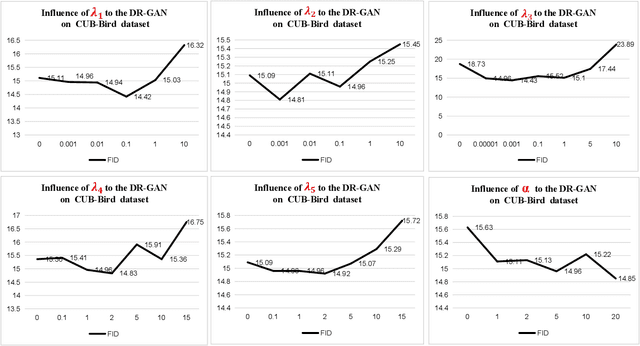

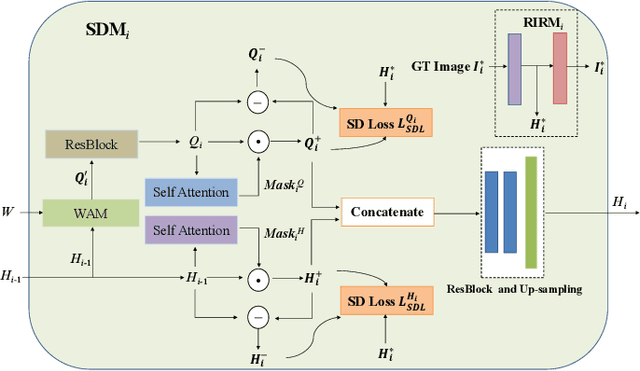
This paper presents a new Text-to-Image generation model, named Distribution Regularization Generative Adversarial Network (DR-GAN), to generate images from text descriptions from improved distribution learning. In DR-GAN, we introduce two novel modules: a Semantic Disentangling Module (SDM) and a Distribution Normalization Module (DNM). SDM combines the spatial self-attention mechanism and a new Semantic Disentangling Loss (SDL) to help the generator distill key semantic information for the image generation. DNM uses a Variational Auto-Encoder (VAE) to normalize and denoise the image latent distribution, which can help the discriminator better distinguish synthesized images from real images. DNM also adopts a Distribution Adversarial Loss (DAL) to guide the generator to align with normalized real image distributions in the latent space. Extensive experiments on two public datasets demonstrated that our DR-GAN achieved a competitive performance in the Text-to-Image task.