 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwin MAE: Masked Autoencoders for Small Datasets
Jan 05, 2023The development of deep learning models in medical image analysis is majorly limited by the lack of large-sized and well-annotated datasets. Unsupervised learning does not require labels and is more suitable for solving medical image analysis problems. However, most of the current unsupervised learning methods need to be applied to large datasets. To make unsupervised learning applicable to small datasets, we proposed Swin MAE, which is a masked autoencoder with Swin Transformer as its backbone. Even on a dataset of only a few thousand medical images and without using any pre-trained models, Swin MAE is still able to learn useful semantic features purely from images. It can equal or even slightly outperform the supervised model obtained by Swin Transformer trained on ImageNet in terms of the transfer learning results of downstream tasks. The code is publicly available at https://github.com/Zian-Xu/Swin-MAE.
An Anatomy-aware Framework for Automatic Segmentation of Parotid Tumor from Multimodal MRI
Oct 04, 2022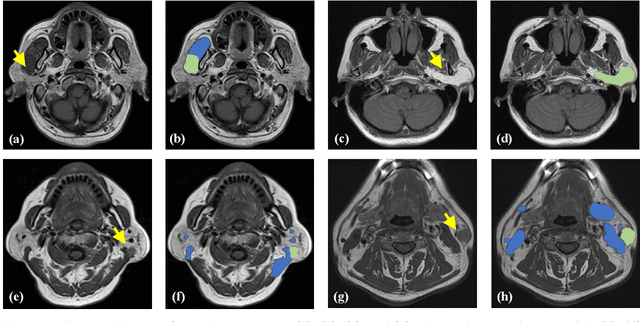
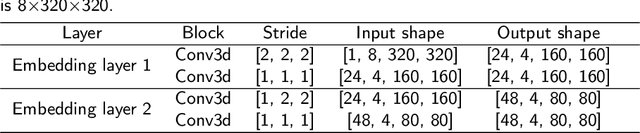
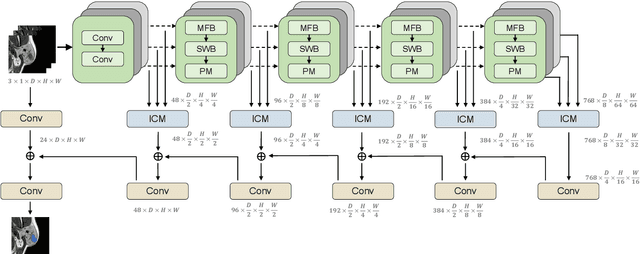

Magnetic Resonance Imaging (MRI) plays an important role in diagnosing the parotid tumor, where accurate segmentation of tumors is highly desired for determining appropriate treatment plans and avoiding unnecessary surgery. However, the task remains nontrivial and challenging due to ambiguous boundaries and various sizes of the tumor, as well as the presence of a large number of anatomical structures around the parotid gland that are similar to the tumor. To overcome these problems, we propose a novel anatomy-aware framework for automatic segmentation of parotid tumors from multimodal MRI. First, a Transformer-based multimodal fusion network PT-Net is proposed in this paper. The encoder of PT-Net extracts and fuses contextual information from three modalities of MRI from coarse to fine, to obtain cross-modality and multi-scale tumor information. The decoder stacks the feature maps of different modalities and calibrates the multimodal information using the channel attention mechanism. Second, considering that the segmentation model is prone to be disturbed by similar anatomical structures and make wrong predictions, we design anatomy-aware loss. By calculating the distance between the activation regions of the prediction segmentation and the ground truth, our loss function forces the model to distinguish similar anatomical structures with the tumor and make correct predictions. Extensive experiments with MRI scans of the parotid tumor showed that our PT-Net achieved higher segmentation accuracy than existing networks. The anatomy-aware loss outperformed state-of-the-art loss functions for parotid tumor segmentation. Our framework can potentially improve the quality of preoperative diagnosis and surgery planning of parotid tumors.
Parotid Gland MR Image Segmentation Based on Contrastive Learning
Aug 26, 2022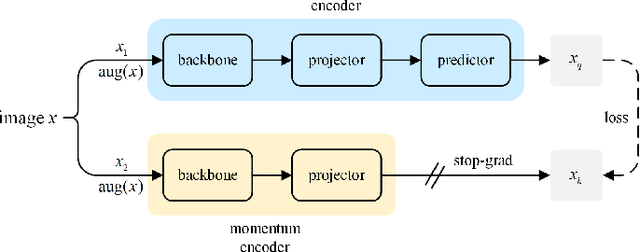

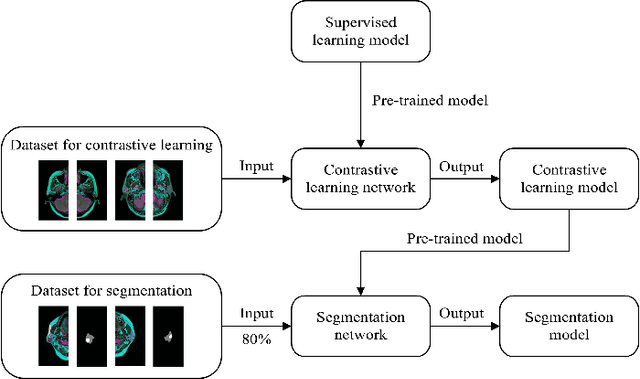
Compared with natural images, medical images are difficult to acquire and costly to label. Contrastive learning, as an unsupervised learning method, can more effectively utilize unlabeled medical images. In this paper, we used a Transformer-based contrastive learning method and innovatively trained the contrastive learning network with transfer learning. Then, the output model was transferred to the downstream parotid segmentation task, which improved the performance of the parotid segmentation model on the test set. The improved DSC was 89.60%, MPA was 99.36%, MIoU was 85.11%, and HD was 2.98. All four metrics showed significant improvement compared to the results of using a supervised learning model as a pre-trained model for the parotid segmentation network. In addition, we found that the improvement of the segmentation network by the contrastive learning model was mainly in the encoder part, so this paper also tried to build a contrastive learning network for the decoder part and discussed the problems encountered in the process of building.
Parotid Gland MRI Segmentation Based on Swin-Unet and Multimodal Images
Jun 07, 2022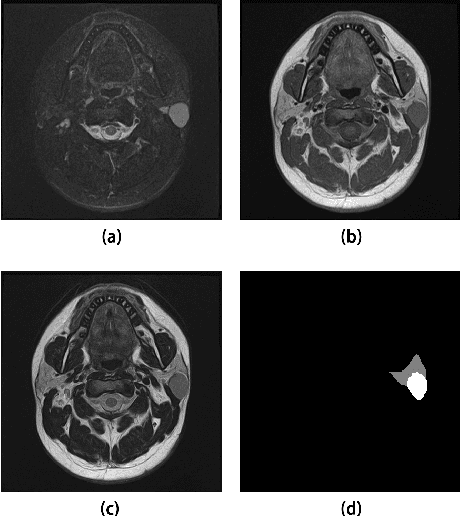
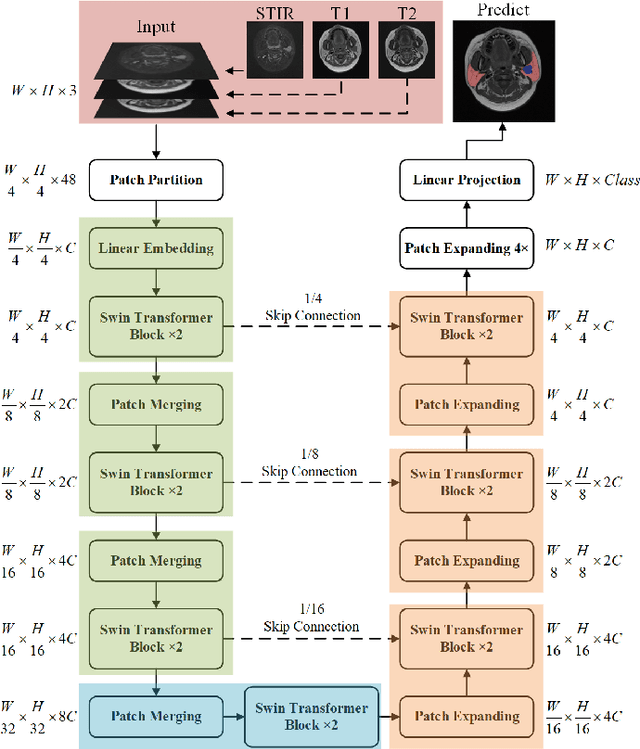
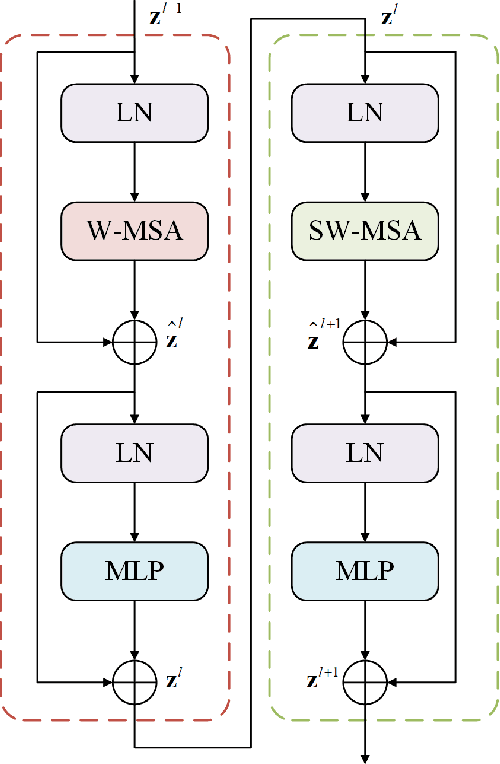
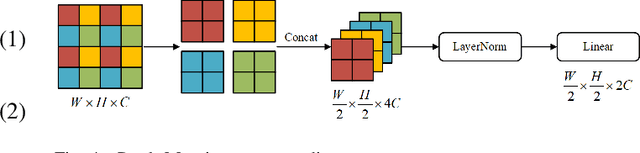
Parotid gland tumors account for approximately 2% to 10% of head and neck tumors. Preoperative tumor localization, differential diagnosis, and subsequent selection of appropriate treatment for parotid gland tumors is critical. However, the relative rarity of these tumors and the highly dispersed tissue types have left an unmet need for a subtle differential diagnosis of such neoplastic lesions based on preoperative radiomics. Recently, deep learning methods have developed rapidly, especially Transformer beats the traditional convolutional neural network in computer vision. Many new Transformer-based networks have been proposed for computer vision tasks. In this study, multicenter multimodal parotid gland MRI images were collected. The Swin-Unet which was based on Transformer was used. MRI images of STIR, T1 and T2 modalities were combined into a three-channel data to train the network. We achieved segmentation of the region of interest for parotid gland and tumor. The DSC of the model on the test set was 88.63%, MPA was 99.31%, MIoU was 83.99%, and HD was 3.04. Then a series of comparison experiments were designed in this paper to further validate the segmentation performance of the algorithm.
Mutual Attention-based Hybrid Dimensional Network for Multimodal Imaging Computer-aided Diagnosis
Jan 24, 2022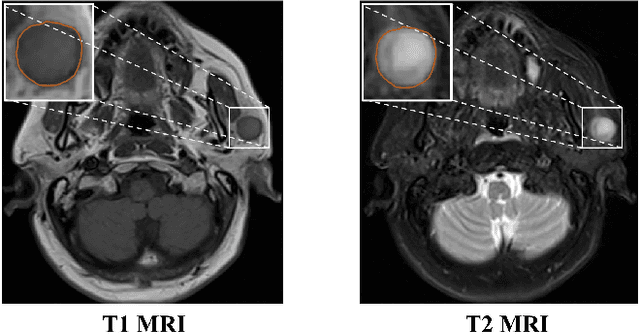
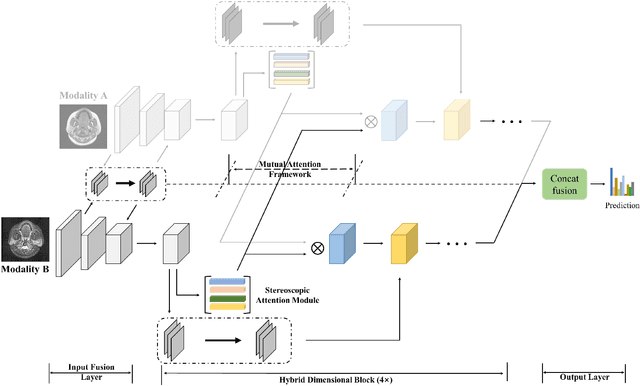
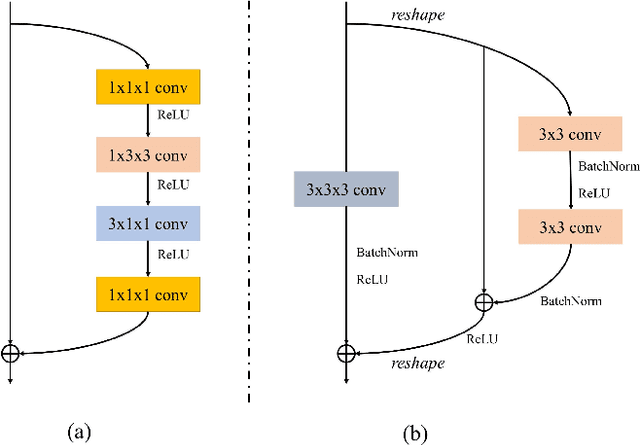
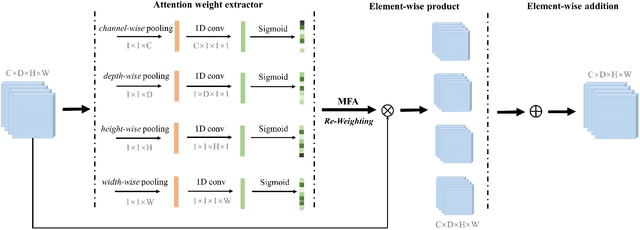
Recent works on Multimodal 3D Computer-aided diagnosis have demonstrated that obtaining a competitive automatic diagnosis model when a 3D convolution neural network (CNN) brings more parameters and medical images are scarce remains nontrivial and challenging. Considering both consistencies of regions of interest in multimodal images and diagnostic accuracy, we propose a novel mutual attention-based hybrid dimensional network for MultiModal 3D medical image classification (MMNet). The hybrid dimensional network integrates 2D CNN with 3D convolution modules to generate deeper and more informative feature maps, and reduce the training complexity of 3D fusion. Besides, the pre-trained model of ImageNet can be used in 2D CNN, which improves the performance of the model. The stereoscopic attention is focused on building rich contextual interdependencies of the region in 3D medical images. To improve the regional correlation of pathological tissues in multimodal medical images, we further design a mutual attention framework in the network to build the region-wise consistency in similar stereoscopic regions of different image modalities, providing an implicit manner to instruct the network to focus on pathological tissues. MMNet outperforms many previous solutions and achieves results competitive to the state-of-the-art on three multimodal imaging datasets, i.e., Parotid Gland Tumor (PGT) dataset, the MRNet dataset, and the PROSTATEx dataset, and its advantages are validated by extensive experiments.