 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Instinctive Bias: Spurious Images lead to Hallucination in MLLMs
Paper and Code


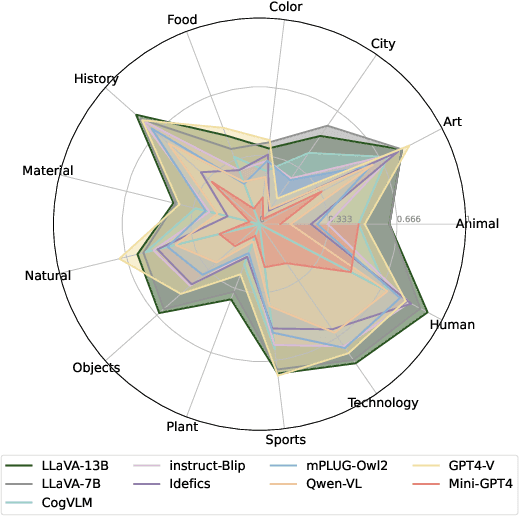

Large language models (LLMs) have recently experienced remarkable progress, where the advent of multi-modal large language models (MLLMs) has endowed LLMs with visual capabilities, leading to impressive performances in various multi-modal tasks. However, those powerful MLLMs such as GPT-4V still fail spectacularly when presented with certain image and text inputs. In this paper, we identify a typical class of inputs that baffles MLLMs, which consist of images that are highly relevant but inconsistent with answers, causing MLLMs to suffer from hallucination. To quantify the effect, we propose CorrelationQA, the first benchmark that assesses the hallucination level given spurious images. This benchmark contains 7,308 text-image pairs across 13 categories. Based on the proposed CorrelationQA, we conduct a thorough analysis on 9 mainstream MLLMs, illustrating that they universally suffer from this instinctive bias to varying degrees. We hope that our curated benchmark and evaluation results aid in better assessments of the MLLMs' robustness in the presence of misleading images. The resource is available in https://github.com/MasaiahHan/CorrelationQA.