 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-Supervised Monocular Depth Estimationwith Resolution-Mismatched Data
Paper and Code
Sep 23, 2021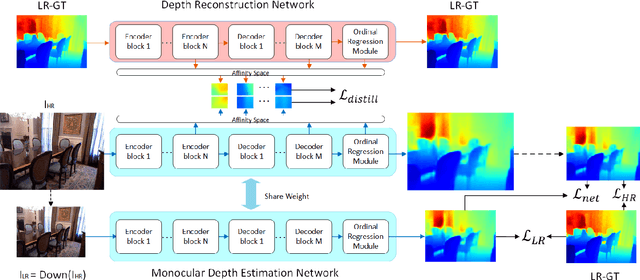



Depth estimation from a single image is an active research topic in computer vision. The most accurate approaches are based on fully supervised learning models, which rely on a large amount of dense and high-resolution (HR) ground-truth depth maps. However, in practice, color images are usually captured with much higher resolution than depth maps, leading to the resolution-mismatched effect. In this paper, we propose a novel weakly-supervised framework to train a monocular depth estimation network to generate HR depth maps with resolution-mismatched supervision, i.e., the inputs are HR color images and the ground-truth are low-resolution (LR) depth maps. The proposed weakly supervised framework is composed of a sharing weight monocular depth estimation network and a depth reconstruction network for distillation. Specifically, for the monocular depth estimation network the input color image is first downsampled to obtain its LR version with the same resolution as the ground-truth depth. Then, both HR and LR color images are fed into the proposed monocular depth estimation network to obtain the corresponding estimated depth maps. We introduce three losses to train the network: 1) reconstruction loss between the estimated LR depth and the ground-truth LR depth; 2) reconstruction loss between the downsampled estimated HR depth and the ground-truth LR depth; 3) consistency loss between the estimated LR depth and the downsampled estimated HR depth. In addition, we design a depth reconstruction network from depth to depth. Through distillation loss, features between two networks maintain the structural consistency in affinity space, and finally improving the estimation network performance. Experimental results demonstrate that our method achieves superior performance than unsupervised and semi-supervised learning based schemes, and is competitive or even better compared to supervised ones.