 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Attacks to Multi-Modal Models
Paper and Code
Sep 10, 2024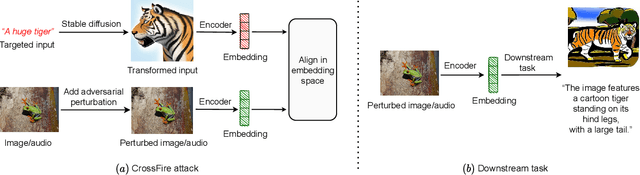



Multi-modal models have gained significant attention due to their powerful capabilities. These models effectively align embeddings across diverse data modalities, showcasing superior performance in downstream tasks compared to their unimodal counterparts. Recent study showed that the attacker can manipulate an image or audio file by altering it in such a way that its embedding matches that of an attacker-chosen targeted input, thereby deceiving downstream models. However, this method often underperforms due to inherent disparities in data from different modalities. In this paper, we introduce CrossFire, an innovative approach to attack multi-modal models. CrossFire begins by transforming the targeted input chosen by the attacker into a format that matches the modality of the original image or audio file. We then formulate our attack as an optimization problem, aiming to minimize the angular deviation between the embeddings of the transformed input and the modified image or audio file. Solving this problem determines the perturbations to be added to the original media. Our extensive experiments on six real-world benchmark datasets reveal that CrossFire can significantly manipulate downstream tasks, surpassing existing attacks. Additionally, we evaluate six defensive strategies against CrossFire, finding that current defenses are insufficient to counteract our CrossFire.