 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysing Fairness of Privacy-Utility Mobility Models
Apr 10, 2023



Preserving the individuals' privacy in sharing spatial-temporal datasets is critical to prevent re-identification attacks based on unique trajectories. Existing privacy techniques tend to propose ideal privacy-utility tradeoffs, however, largely ignore the fairness implications of mobility models and whether such techniques perform equally for different groups of users. The quantification between fairness and privacy-aware models is still unclear and there barely exists any defined sets of metrics for measuring fairness in the spatial-temporal context. In this work, we define a set of fairness metrics designed explicitly for human mobility, based on structural similarity and entropy of the trajectories. Under these definitions, we examine the fairness of two state-of-the-art privacy-preserving models that rely on GAN and representation learning to reduce the re-identification rate of users for data sharing. Our results show that while both models guarantee group fairness in terms of demographic parity, they violate individual fairness criteria, indicating that users with highly similar trajectories receive disparate privacy gain. We conclude that the tension between the re-identification task and individual fairness needs to be considered for future spatial-temporal data analysis and modelling to achieve a privacy-preserving fairness-aware setting.
Privacy-Aware Adversarial Network in Human Mobility Prediction
Aug 09, 2022
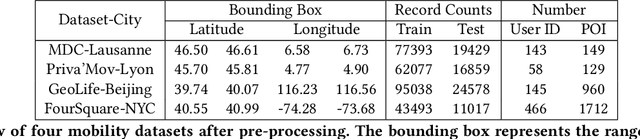

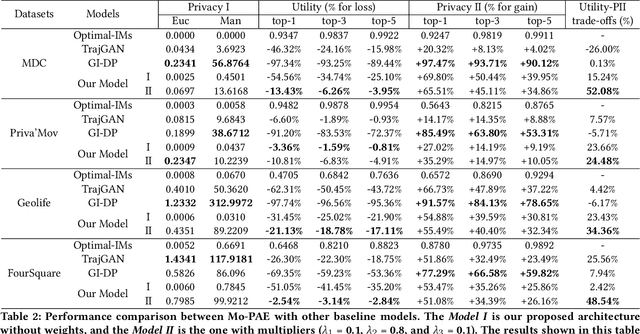
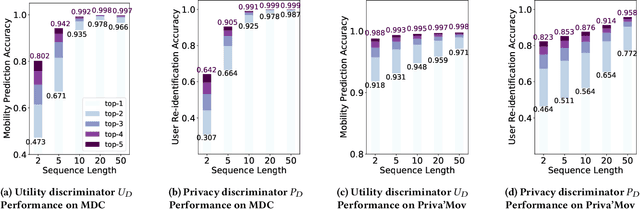
As mobile devices and location-based services are increasingly developed in different smart city scenarios and applications, many unexpected privacy leakages have arisen due to geolocated data collection and sharing. User re-identification and other sensitive inferences are major privacy threats when geolocated data are shared with cloud-assisted applications. Significantly, four spatio-temporal points are enough to uniquely identify 95\% of the individuals, which exacerbates personal information leakages. To tackle malicious purposes such as user re-identification, we propose an LSTM-based adversarial mechanism with representation learning to attain a privacy-preserving feature representation of the original geolocated data (i.e., mobility data) for a sharing purpose. These representations aim to maximally reduce the chance of user re-identification and full data reconstruction with a minimal utility budget (i.e., loss). We train the mechanism by quantifying privacy-utility trade-off of mobility datasets in terms of trajectory reconstruction risk, user re-identification risk, and mobility predictability. We report an exploratory analysis that enables the user to assess this trade-off with a specific loss function and its weight parameters. The extensive comparison results on four representative mobility datasets demonstrate the superiority of our proposed architecture in mobility privacy protection and the efficiency of the proposed privacy-preserving features extractor. We show that the privacy of mobility traces attains decent protection at the cost of marginal mobility utility. Our results also show that by exploring the Pareto optimal setting, we can simultaneously increase both privacy (45%) and utility (32%).
Privacy-Aware Human Mobility Prediction via Adversarial Networks
Jan 19, 2022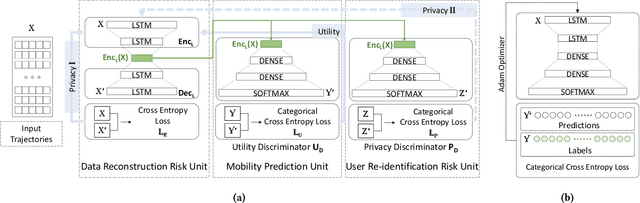

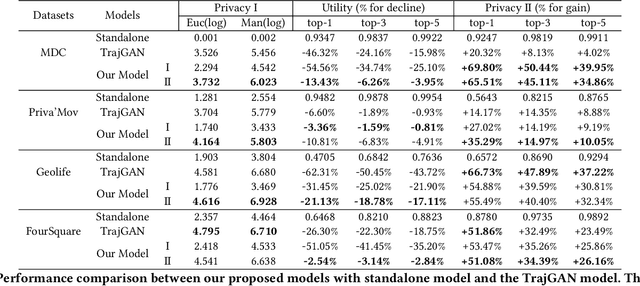
As various mobile devices and location-based services are increasingly developed in different smart city scenarios and applications, many unexpected privacy leakages have arisen due to geolocated data collection and sharing. While these geolocated data could provide a rich understanding of human mobility patterns and address various societal research questions, privacy concerns for users' sensitive information have limited their utilization. In this paper, we design and implement a novel LSTM-based adversarial mechanism with representation learning to attain a privacy-preserving feature representation of the original geolocated data (mobility data) for a sharing purpose. We quantify the utility-privacy trade-off of mobility datasets in terms of trajectory reconstruction risk, user re-identification risk, and mobility predictability. Our proposed architecture reports a Pareto Frontier analysis that enables the user to assess this trade-off as a function of Lagrangian loss weight parameters. The extensive comparison results on four representative mobility datasets demonstrate the superiority of our proposed architecture and the efficiency of the proposed privacy-preserving features extractor. Our results show that by exploring Pareto optimal setting, we can simultaneously increase both privacy (45%) and utility (32%).