 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Adversarial Text Attacks on BERT Models with Projected Gradient Descent
Paper and Code
Jul 29, 2024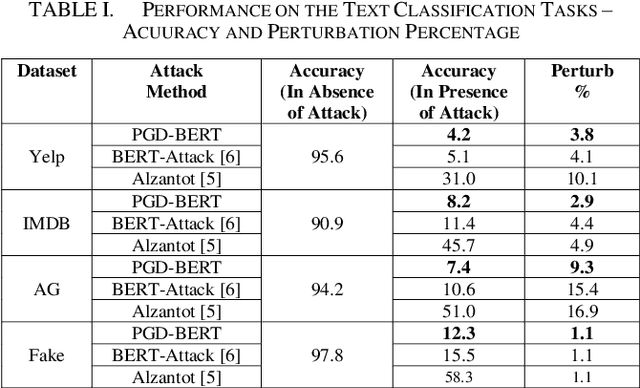
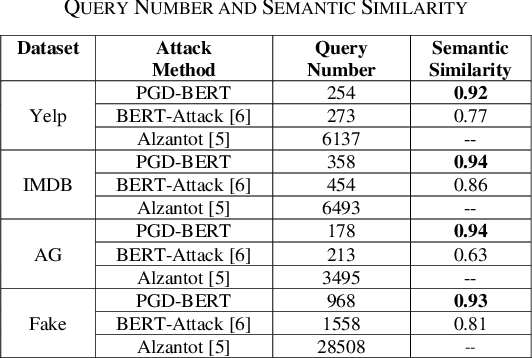
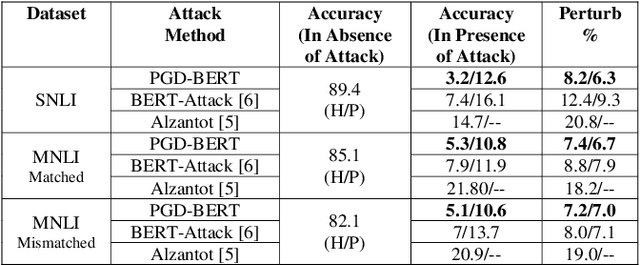

Adversarial attacks against deep learning models represent a major threat to the security and reliability of natural language processing (NLP) systems. In this paper, we propose a modification to the BERT-Attack framework, integrating Projected Gradient Descent (PGD) to enhance its effectiveness and robustness. The original BERT-Attack, designed for generating adversarial examples against BERT-based models, suffers from limitations such as a fixed perturbation budget and a lack of consideration for semantic similarity. The proposed approach in this work, PGD-BERT-Attack, addresses these limitations by leveraging PGD to iteratively generate adversarial examples while ensuring both imperceptibility and semantic similarity to the original input. Extensive experiments are conducted to evaluate the performance of PGD-BERT-Attack compared to the original BERT-Attack and other baseline methods. The results demonstrate that PGD-BERT-Attack achieves higher success rates in causing misclassification while maintaining low perceptual changes. Furthermore, PGD-BERT-Attack produces adversarial instances that exhibit greater semantic resemblance to the initial input, enhancing their applicability in real-world scenarios. Overall, the proposed modification offers a more effective and robust approach to adversarial attacks on BERT-based models, thus contributing to the advancement of defense against attacks on NLP systems.