 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussianAnything: Interactive Point Cloud Latent Diffusion for 3D Generation
Paper and Code

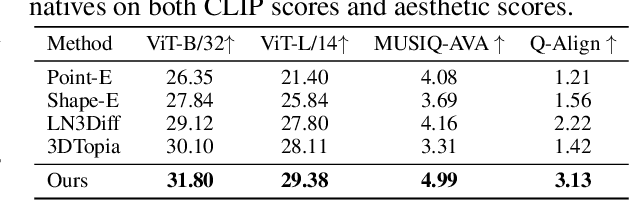


While 3D content generation has advanced significantly, existing methods still face challenges with input formats, latent space design, and output representations. This paper introduces a novel 3D generation framework that addresses these challenges, offering scalable, high-quality 3D generation with an interactive Point Cloud-structured Latent space. Our framework employs a Variational Autoencoder (VAE) with multi-view posed RGB-D(epth)-N(ormal) renderings as input, using a unique latent space design that preserves 3D shape information, and incorporates a cascaded latent diffusion model for improved shape-texture disentanglement. The proposed method, GaussianAnything, supports multi-modal conditional 3D generation, allowing for point cloud, caption, and single/multi-view image inputs. Notably, the newly proposed latent space naturally enables geometry-texture disentanglement, thus allowing 3D-aware editing. Experimental results demonstrate the effectiveness of our approach on multiple datasets, outperforming existing methods in both text- and image-conditioned 3D generation.