 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2025 Challenge on HR Depth from Images of Specular and Transparent Surfaces
Jun 06, 2025This paper reports on the NTIRE 2025 challenge on HR Depth From images of Specular and Transparent surfaces, held in conjunction with the New Trends in Image Restoration and Enhancement (NTIRE) workshop at CVPR 2025. This challenge aims to advance the research on depth estimation, specifically to address two of the main open issues in the field: high-resolution and non-Lambertian surfaces. The challenge proposes two tracks on stereo and single-image depth estimation, attracting about 177 registered participants. In the final testing stage, 4 and 4 participating teams submitted their models and fact sheets for the two tracks.
The Fourth Monocular Depth Estimation Challenge
Apr 24, 2025


This paper presents the results of the fourth edition of the Monocular Depth Estimation Challenge (MDEC), which focuses on zero-shot generalization to the SYNS-Patches benchmark, a dataset featuring challenging environments in both natural and indoor settings. In this edition, we revised the evaluation protocol to use least-squares alignment with two degrees of freedom to support disparity and affine-invariant predictions. We also revised the baselines and included popular off-the-shelf methods: Depth Anything v2 and Marigold. The challenge received a total of 24 submissions that outperformed the baselines on the test set; 10 of these included a report describing their approach, with most leading methods relying on affine-invariant predictions. The challenge winners improved the 3D F-Score over the previous edition's best result, raising it from 22.58% to 23.05%.
Learning Content-Aware Multi-Modal Joint Input Pruning via Bird's-Eye-View Representation
Oct 09, 2024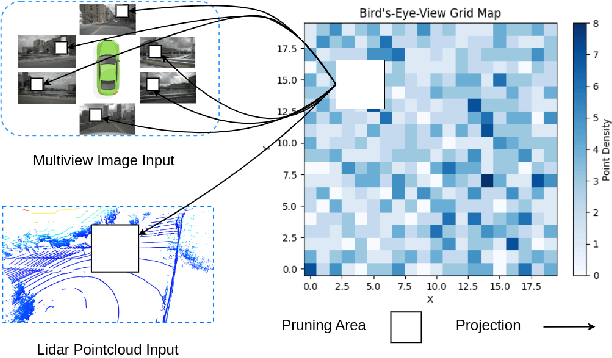
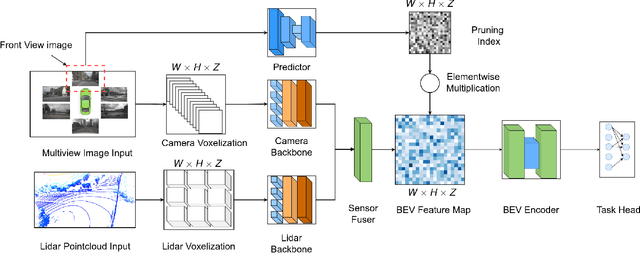
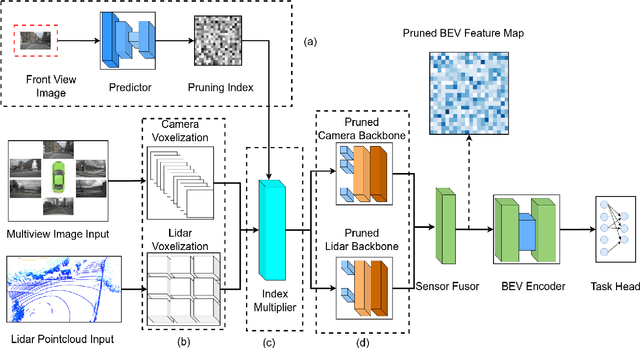
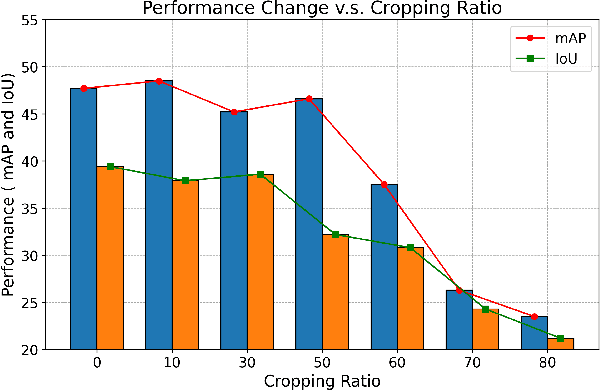
In the landscape of autonomous driving, Bird's-Eye-View (BEV) representation has recently garnered substantial academic attention, serving as a transformative framework for the fusion of multi-modal sensor inputs. This BEV paradigm effectively shifts the sensor fusion challenge from a rule-based methodology to a data-centric approach, thereby facilitating more nuanced feature extraction from an array of heterogeneous sensors. Notwithstanding its evident merits, the computational overhead associated with BEV-based techniques often mandates high-capacity hardware infrastructures, thus posing challenges for practical, real-world implementations. To mitigate this limitation, we introduce a novel content-aware multi-modal joint input pruning technique. Our method leverages BEV as a shared anchor to algorithmically identify and eliminate non-essential sensor regions prior to their introduction into the perception model's backbone. We validatethe efficacy of our approach through extensive experiments on the NuScenes dataset, demonstrating substantial computational efficiency without sacrificing perception accuracy. To the best of our knowledge, this work represents the first attempt to alleviate the computational burden from the input pruning point.
QuadBEV: An Efficient Quadruple-Task Perception Framework via Bird's-Eye-View Representation
Oct 09, 2024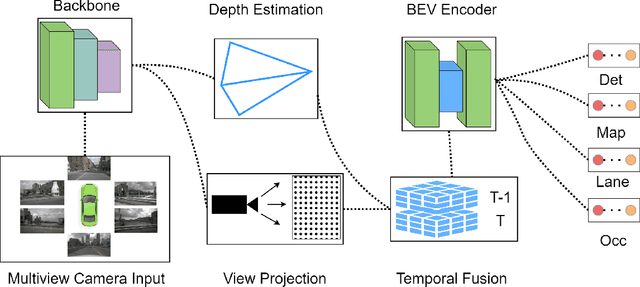
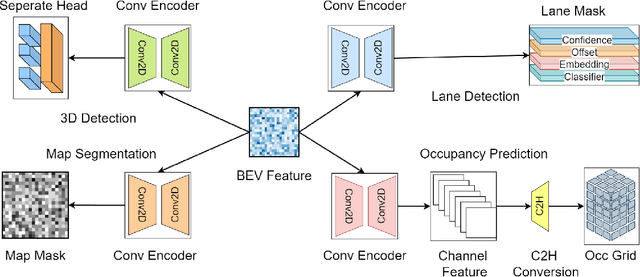
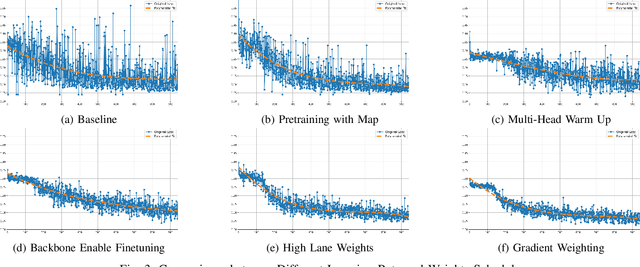
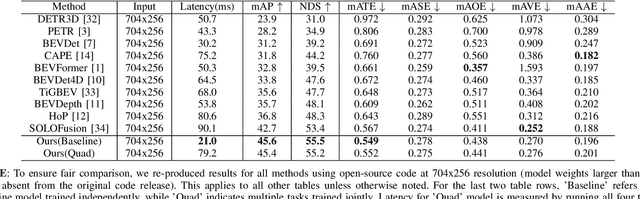
Bird's-Eye-View (BEV) perception has become a vital component of autonomous driving systems due to its ability to integrate multiple sensor inputs into a unified representation, enhancing performance in various downstream tasks. However, the computational demands of BEV models pose challenges for real-world deployment in vehicles with limited resources. To address these limitations, we propose QuadBEV, an efficient multitask perception framework that leverages the shared spatial and contextual information across four key tasks: 3D object detection, lane detection, map segmentation, and occupancy prediction. QuadBEV not only streamlines the integration of these tasks using a shared backbone and task-specific heads but also addresses common multitask learning challenges such as learning rate sensitivity and conflicting task objectives. Our framework reduces redundant computations, thereby enhancing system efficiency, making it particularly suited for embedded systems. We present comprehensive experiments that validate the effectiveness and robustness of QuadBEV, demonstrating its suitability for real-world applications.
Towards Efficient 3D Object Detection in Bird's-Eye-View Space for Autonomous Driving: A Convolutional-Only Approach
Dec 01, 2023



3D object detection in Bird's-Eye-View (BEV) space has recently emerged as a prevalent approach in the field of autonomous driving. Despite the demonstrated improvements in accuracy and velocity estimation compared to perspective view methods, the deployment of BEV-based techniques in real-world autonomous vehicles remains challenging. This is primarily due to their reliance on vision-transformer (ViT) based architectures, which introduce quadratic complexity with respect to the input resolution. To address this issue, we propose an efficient BEV-based 3D detection framework called BEVENet, which leverages a convolutional-only architectural design to circumvent the limitations of ViT models while maintaining the effectiveness of BEV-based methods. Our experiments show that BEVENet is 3$\times$ faster than contemporary state-of-the-art (SOTA) approaches on the NuScenes challenge, achieving a mean average precision (mAP) of 0.456 and a nuScenes detection score (NDS) of 0.555 on the NuScenes validation dataset, with an inference speed of 47.6 frames per second. To the best of our knowledge, this study stands as the first to achieve such significant efficiency improvements for BEV-based methods, highlighting their enhanced feasibility for real-world autonomous driving applications.
Dataset vs Reality: Understanding Model Performance from the Perspective of Information Need
Dec 06, 2022Deep learning technologies have brought us many models that outperform human beings on a few benchmarks. An interesting question is: can these models well solve real-world problems with similar settings (e.g., same input/output) to the benchmark datasets? We argue that a model is trained to answer the same information need for which the training dataset is created. Although some datasets may share high structural similarities, e.g., question-answer pairs for the question answering (QA) task and image-caption pairs for the image captioning (IC) task, not all datasets are created for the same information need. To support our argument, we conduct a comprehensive analysis on widely used benchmark datasets for both QA and IC tasks. We compare the dataset creation process (e.g., crowdsourced, or collected data from real users or content providers) from the perspective of information need in the context of information retrieval. To show the differences between datasets, we perform both word-level and sentence-level analysis. We show that data collected from real users or content providers tend to have richer, more diverse, and more specific words than data annotated by crowdworkers. At sentence level, data by crowdworkers share similar dependency distributions and higher similarities in sentence structure, compared to data collected from content providers. We believe our findings could partially explain why some datasets are considered more challenging than others, for similar tasks. Our findings may also be helpful in guiding new dataset construction.