 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Content-Aware Multi-Modal Joint Input Pruning via Bird's-Eye-View Representation
Paper and Code
Oct 09, 2024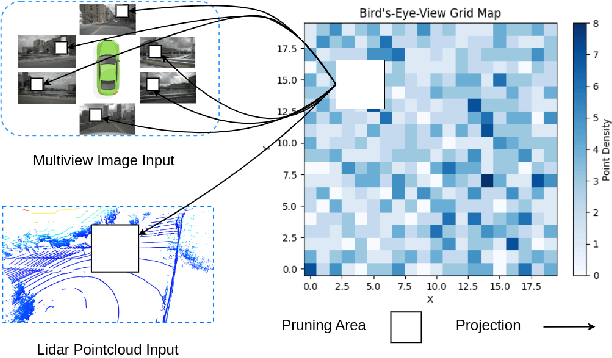
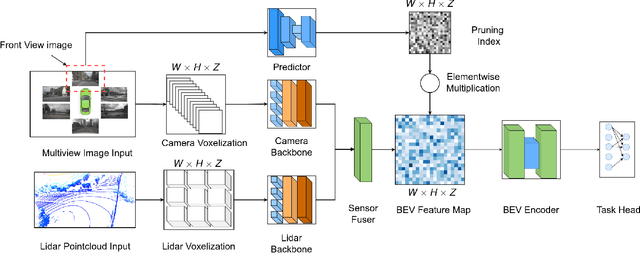
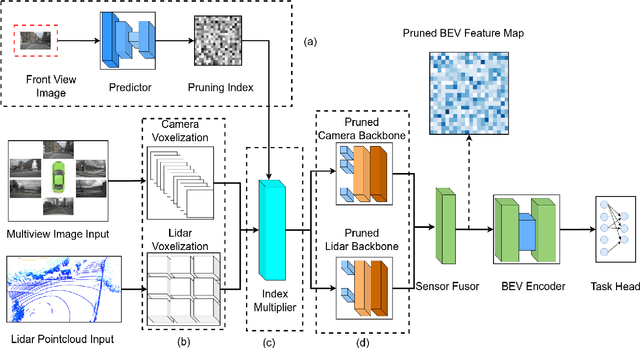
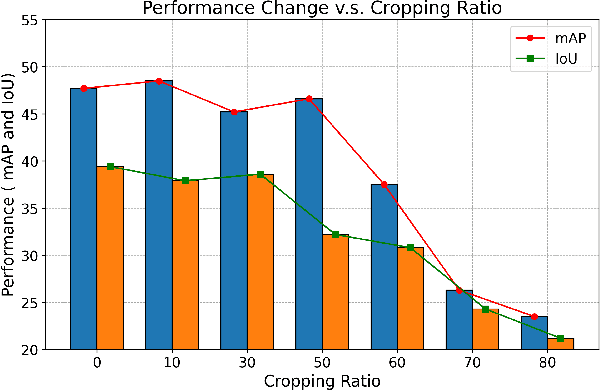
In the landscape of autonomous driving, Bird's-Eye-View (BEV) representation has recently garnered substantial academic attention, serving as a transformative framework for the fusion of multi-modal sensor inputs. This BEV paradigm effectively shifts the sensor fusion challenge from a rule-based methodology to a data-centric approach, thereby facilitating more nuanced feature extraction from an array of heterogeneous sensors. Notwithstanding its evident merits, the computational overhead associated with BEV-based techniques often mandates high-capacity hardware infrastructures, thus posing challenges for practical, real-world implementations. To mitigate this limitation, we introduce a novel content-aware multi-modal joint input pruning technique. Our method leverages BEV as a shared anchor to algorithmically identify and eliminate non-essential sensor regions prior to their introduction into the perception model's backbone. We validatethe efficacy of our approach through extensive experiments on the NuScenes dataset, demonstrating substantial computational efficiency without sacrificing perception accuracy. To the best of our knowledge, this work represents the first attempt to alleviate the computational burden from the input pruning point.