 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferability of Representations Learned using Supervised Contrastive Learning Trained on a Multi-Domain Dataset
Sep 27, 2023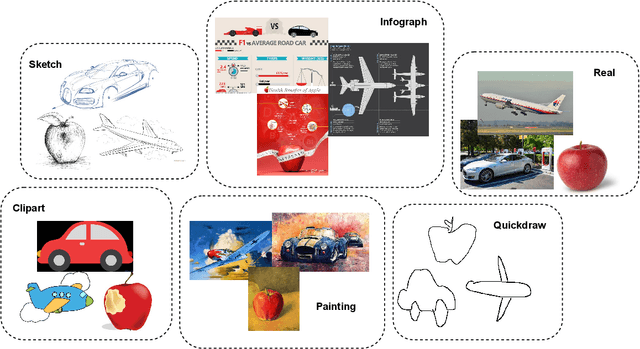
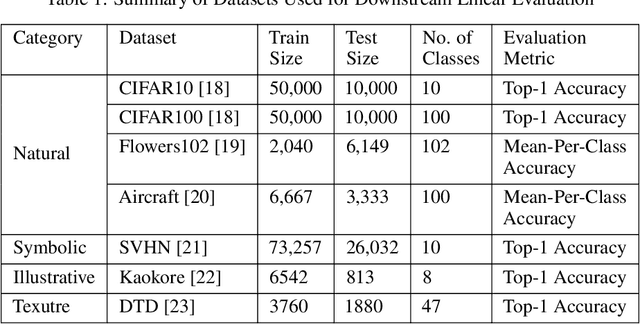
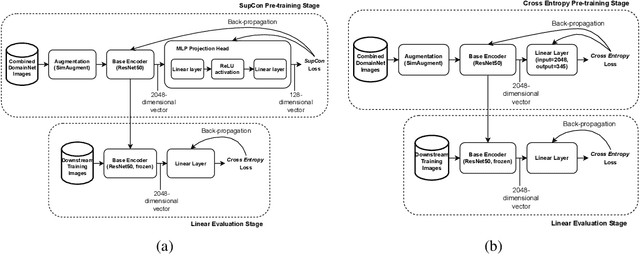

Contrastive learning has shown to learn better quality representations than models trained using cross-entropy loss. They also transfer better to downstream datasets from different domains. However, little work has been done to explore the transferability of representations learned using contrastive learning when trained on a multi-domain dataset. In this paper, a study has been conducted using the Supervised Contrastive Learning framework to learn representations from the multi-domain DomainNet dataset and then evaluate the transferability of the representations learned on other downstream datasets. The fixed feature linear evaluation protocol will be used to evaluate the transferability on 7 downstream datasets that were chosen across different domains. The results obtained are compared to a baseline model that was trained using the widely used cross-entropy loss. Empirical results from the experiments showed that on average, the Supervised Contrastive Learning model performed 6.05% better than the baseline model on the 7 downstream datasets. The findings suggest that Supervised Contrastive Learning models can potentially learn more robust representations that transfer better across domains than cross-entropy models when trained on a multi-domain dataset.
Tackling VQA with Pretrained Foundation Models without Further Training
Sep 27, 2023



Large language models (LLMs) have achieved state-of-the-art results in many natural language processing tasks. They have also demonstrated ability to adapt well to different tasks through zero-shot or few-shot settings. With the capability of these LLMs, researchers have looked into how to adopt them for use with Visual Question Answering (VQA). Many methods require further training to align the image and text embeddings. However, these methods are computationally expensive and requires large scale image-text dataset for training. In this paper, we explore a method of combining pretrained LLMs and other foundation models without further training to solve the VQA problem. The general idea is to use natural language to represent the images such that the LLM can understand the images. We explore different decoding strategies for generating textual representation of the image and evaluate their performance on the VQAv2 dataset.