 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntity-Aware Multimodal Alignment Framework for News Image Captioning
Paper and Code

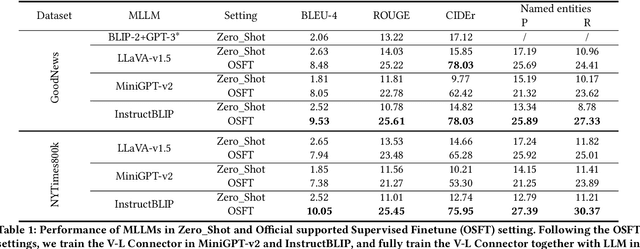
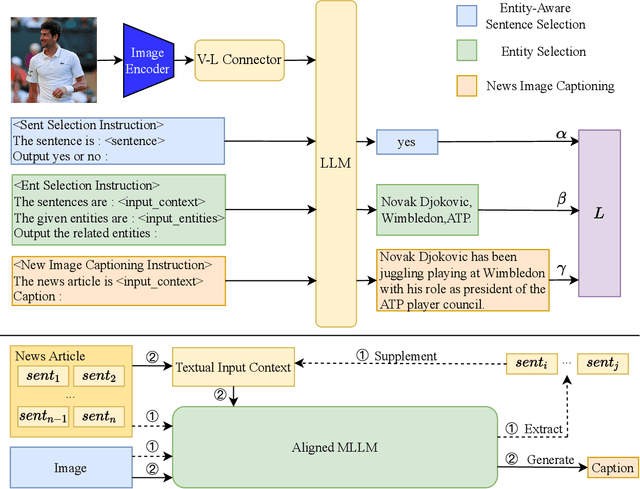
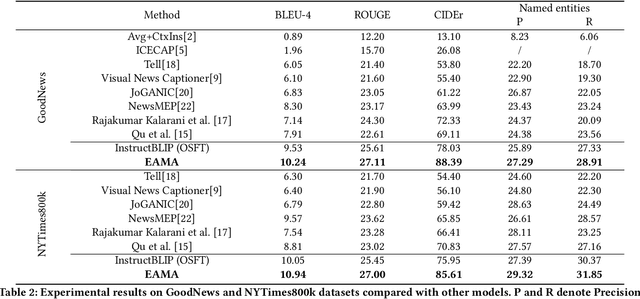
News image captioning task is a variant of image captioning task which requires model to generate a more informative caption with news image and the associated news article. Multimodal Large Language models have developed rapidly in recent years and is promising in news image captioning task. However, according to our experiments, common MLLMs are not good at generating the entities in zero-shot setting. Their abilities to deal with the entities information are still limited after simply fine-tuned on news image captioning dataset. To obtain a more powerful model to handle the multimodal entity information, we design two multimodal entity-aware alignment tasks and an alignment framework to align the model and generate the news image captions. Our method achieves better results than previous state-of-the-art models in CIDEr score (72.33 -> 86.29) on GoodNews dataset and (70.83 -> 85.61) on NYTimes800k dataset.