 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCesarean Scar Defect Segmentation in Transvaginal Ultrasound Images: a Dataset and Benchmark
May 26, 2026Cesarean Scar Defect (CSD) is one of the most prevalent complications following cesarean delivery. Transvaginal ultrasonography is widely used for primary CSD screening. Accurate determination of CSD outline and dimensions is crucial for treatment. However, CSDs are frequently overlooked by sonographers due to small size and irregular morphology, suboptimal image quality, and limited clinical awareness in resource-constrained settings. Despite artificial intelligence advances in medical imaging, no public dataset exists for transvaginal ultrasound CSD segmentation. To address this gap, we present a comprehensive CSD dataset comprising 1,111 images and 16 videos, yielding 501 positive samples with confirmed CSD and precise pixel-level manual annotations. Annotations are performed following standardized clinical guidelines through collaboration between experienced sonographers and trained PhD students. This work provides high-quality benchmark resources for advancing medical image segmentation algorithms and promoting clinical innovation. Ultimately, improved CSD diagnosis and subsequent treatment strategies can enhance the quality of life in women of reproductive age, representing significant value for both medical research and clinical practice.
PEGA: Personality-Guided Preference Aggregator for Ephemeral Group Recommendation
Apr 18, 2023Recently, making recommendations for ephemeral groups which contain dynamic users and few historic interactions have received an increasing number of attention. The main challenge of ephemeral group recommender is how to aggregate individual preferences to represent the group's overall preference. Score aggregation and preference aggregation are two commonly-used methods that adopt hand-craft predefined strategies and data-driven strategies, respectively. However, they neglect to take into account the importance of the individual inherent factors such as personality in the group. In addition, they fail to work well due to a small number of interactive records. To address these issues, we propose a Personality-Guided Preference Aggregator (PEGA) for ephemeral group recommendation. Concretely, we first adopt hyper-rectangle to define the concept of Group Personality. We then use the personality attention mechanism to aggregate group preferences. The role of personality in our approach is twofold: (1) To estimate individual users' importance in a group and provide explainability; (2) to alleviate the data sparsity issue that occurred in ephemeral groups. The experimental results demonstrate that our model significantly outperforms the state-of-the-art methods w.r.t. the score of both Recall and NDCG on Amazon and Yelp datasets.
C3SASR: Cheap Causal Convolutions for Self-Attentive Sequential Recommendation
Nov 10, 2022Sequential Recommendation is a prominent topic in current research, which uses user behavior sequence as an input to predict future behavior. By assessing the correlation strength of historical behavior through the dot product, the model based on the self-attention mechanism can capture the long-term preference of the sequence. However, it has two limitations. On the one hand, it does not effectively utilize the items' local context information when determining the attention and creating the sequence representation. On the other hand, the convolution and linear layers often contain redundant information, which limits the ability to encode sequences. In this paper, we propose a self-attentive sequential recommendation model based on cheap causal convolution. It utilizes causal convolutions to capture items' local information for calculating attention and generating sequence embedding. It also uses cheap convolutions to improve the representations by lightweight structure. We evaluate the effectiveness of the proposed model in terms of both accurate and calibrated sequential recommendation. Experiments on benchmark datasets show that the proposed model can perform better in single- and multi-objective recommendation scenarios.
DACSR: Dual-Aggregation End-to-End Calibrated Sequential Recommendation
Apr 29, 2022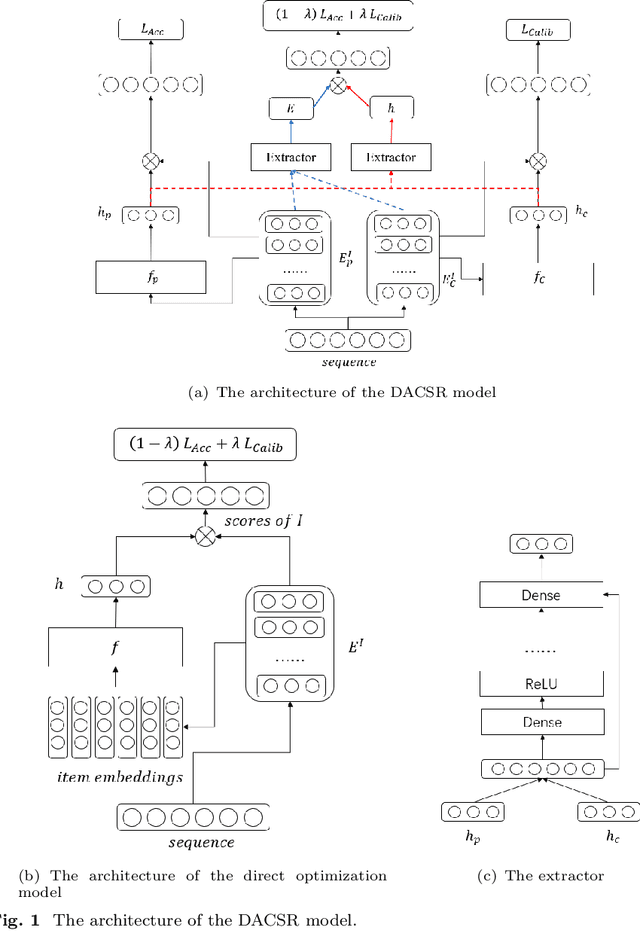
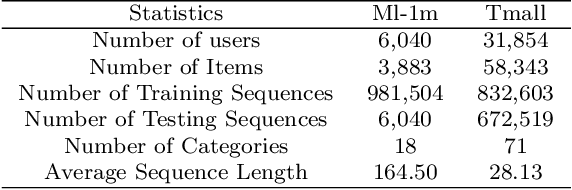
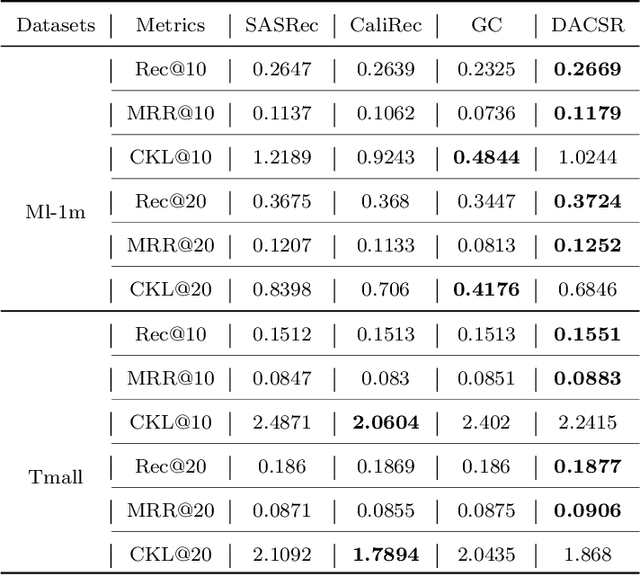
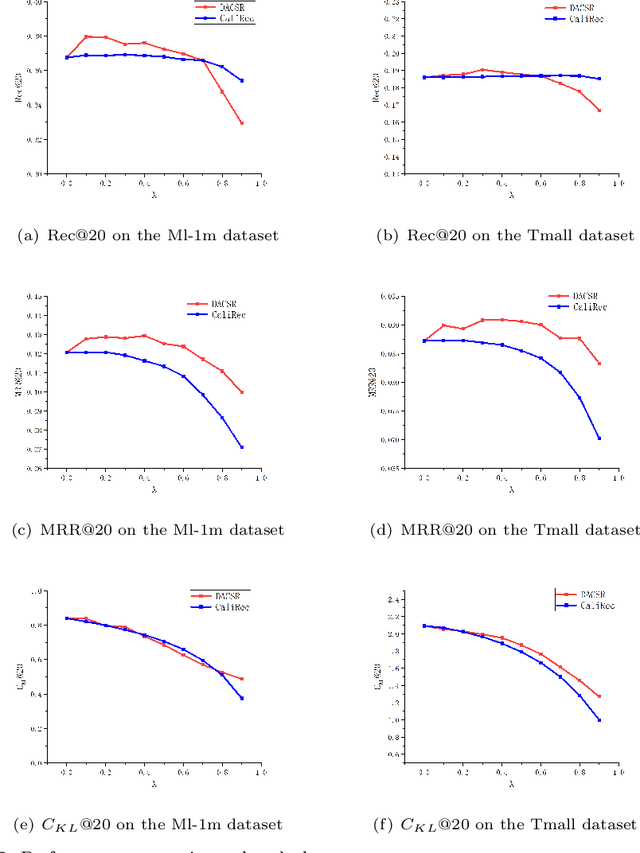
Recent years have witnessed the progress of sequential recommendation in accurately predicting users' future behaviors. However, only persuading accuracy leads to the risk of filter bubbles where recommenders only focus on users' main interest areas. Different from other studies which improve diversity or coverage, we investigate the calibration in sequential recommendation. However, existing calibrated methods followed a post-processing paradigm, which costs more computation time and sacrifices the recommendation accuracy. To this end, we propose an end-to-end framework to provide both accurate and calibrated recommendations. We propose a loss function to measure the divergence of distributions between recommendation lists and historical behaviors for sequential recommendation framework. In addition, we design a dual-aggregation model which extracts information from two individual sequence encoders with different objectives to further improve the recommendation. Experiments on two benchmark datasets demonstrate the effectiveness and efficiency of our model.