 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEagleVision: A Dual-Stage Framework with BEV-grounding-based Chain-of-Thought for Spatial Intelligence
Dec 17, 2025Recent spatial intelligence approaches typically attach 3D cues to 2D reasoning pipelines or couple MLLMs with black-box reconstruction modules, leading to weak spatial consistency, limited viewpoint diversity, and evidence chains that cannot be traced back to supporting views. Frameworks for "thinking with images" (e.g., ChatGPT-o3 and DeepEyes) show that stepwise multimodal reasoning can emerge by interleaving hypothesis formation with active acquisition of visual evidence, but they do not address three key challenges in spatial Chain-of-Thought (CoT): building global space perception under strict token budgets, explicitly associating 3D hypotheses with video frames for verification, and designing spatially grounded rewards for reinforcement learning. To address these issues, we present EagleVision, a dual-stage framework for progressive spatial cognition through macro perception and micro verification. In the macro perception stage, EagleVision employs a semantics-perspective-fusion determinantal point process (SPF-DPP) to select a compact set of geometry- and semantics-aware keyframes from long videos under a fixed token budget. In the micro verification stage, we formalize spatial CoT as BEV-grounded pose querying: the agent iteratively predicts poses on a BEV plane, retrieves the nearest real frames, and is trained purely by reinforcement learning with a spatial grounding reward that scores the consistency between predicted poses and observed views. On VSI-Bench, EagleVision achieves state-of-the-art performance among open-source vision-language models, demonstrating strong and generalizable spatial understanding.
Driving by Hybrid Navigation: An Online HD-SD Map Association Framework and Benchmark for Autonomous Vehicles
Jul 10, 2025



Autonomous vehicles rely on global standard-definition (SD) maps for road-level route planning and online local high-definition (HD) maps for lane-level navigation. However, recent work concentrates on construct online HD maps, often overlooking the association of global SD maps with online HD maps for hybrid navigation, making challenges in utilizing online HD maps in the real world. Observing the lack of the capability of autonomous vehicles in navigation, we introduce \textbf{O}nline \textbf{M}ap \textbf{A}ssociation, the first benchmark for the association of hybrid navigation-oriented online maps, which enhances the planning capabilities of autonomous vehicles. Based on existing datasets, the OMA contains 480k of roads and 260k of lane paths and provides the corresponding metrics to evaluate the performance of the model. Additionally, we propose a novel framework, named Map Association Transformer, as the baseline method, using path-aware attention and spatial attention mechanisms to enable the understanding of geometric and topological correspondences. The code and dataset can be accessed at https://github.com/WallelWan/OMA-MAT.
SP$^2$T: Sparse Proxy Attention for Dual-stream Point Transformer
Dec 16, 2024



In 3D understanding, point transformers have yielded significant advances in broadening the receptive field. However, further enhancement of the receptive field is hindered by the constraints of grouping attention. The proxy-based model, as a hot topic in image and language feature extraction, uses global or local proxies to expand the model's receptive field. But global proxy-based methods fail to precisely determine proxy positions and are not suited for tasks like segmentation and detection in the point cloud, and exist local proxy-based methods for image face difficulties in global-local balance, proxy sampling in various point clouds, and parallel cross-attention computation for sparse association. In this paper, we present SP$^2$T, a local proxy-based dual stream point transformer, which promotes global receptive field while maintaining a balance between local and global information. To tackle robust 3D proxy sampling, we propose a spatial-wise proxy sampling with vertex-based point proxy associations, ensuring robust point-cloud sampling in many scales of point cloud. To resolve economical association computation, we introduce sparse proxy attention combined with table-based relative bias, which enables low-cost and precise interactions between proxy and point features. Comprehensive experiments across multiple datasets reveal that our model achieves SOTA performance in downstream tasks. The code has been released in https://github.com/TerenceWallel/Sparse-Proxy-Point-Transformer .
Unlocking Attributes' Contribution to Successful Camouflage: A Combined Textual and VisualAnalysis Strategy
Aug 22, 2024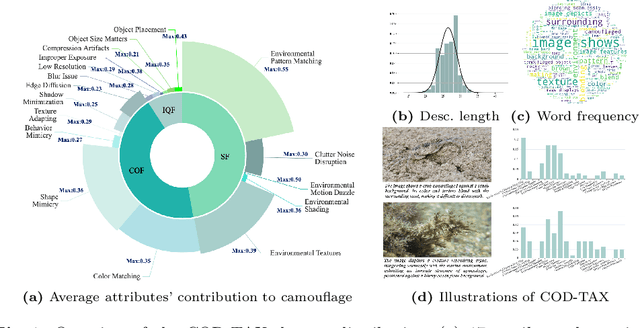
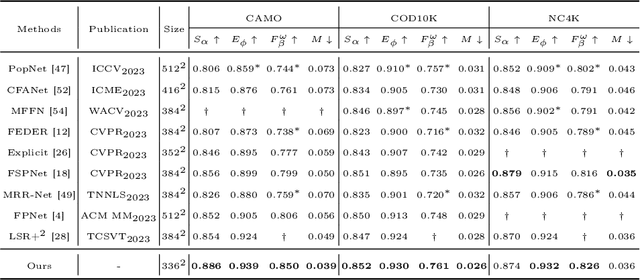
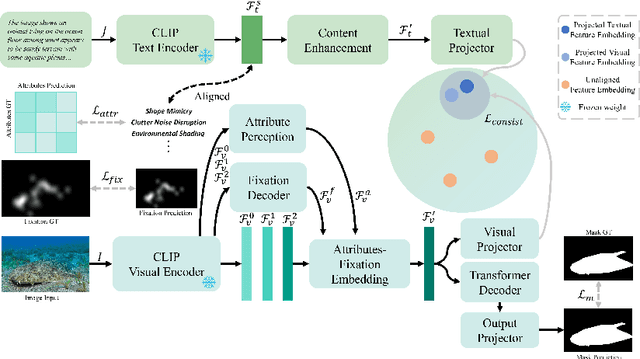
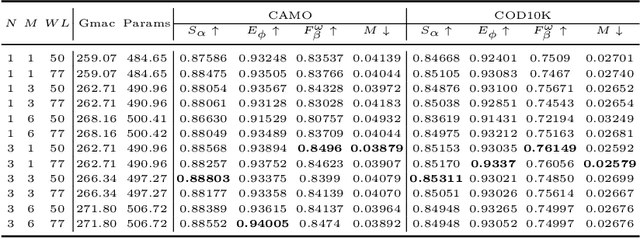
In the domain of Camouflaged Object Segmentation (COS), despite continuous improvements in segmentation performance, the underlying mechanisms of effective camouflage remain poorly understood, akin to a black box. To address this gap, we present the first comprehensive study to examine the impact of camouflage attributes on the effectiveness of camouflage patterns, offering a quantitative framework for the evaluation of camouflage designs. To support this analysis, we have compiled the first dataset comprising descriptions of camouflaged objects and their attribute contributions, termed COD-Text And X-attributions (COD-TAX). Moreover, drawing inspiration from the hierarchical process by which humans process information: from high-level textual descriptions of overarching scenarios, through mid-level summaries of local areas, to low-level pixel data for detailed analysis. We have developed a robust framework that combines textual and visual information for the task of COS, named Attribution CUe Modeling with Eye-fixation Network (ACUMEN). ACUMEN demonstrates superior performance, outperforming nine leading methods across three widely-used datasets. We conclude by highlighting key insights derived from the attributes identified in our study. Code: https://github.com/lyu-yx/ACUMEN.
Foresight of Graph Reinforcement Learning Latent Permutations Learnt by Gumbel Sinkhorn Network
Oct 23, 2021
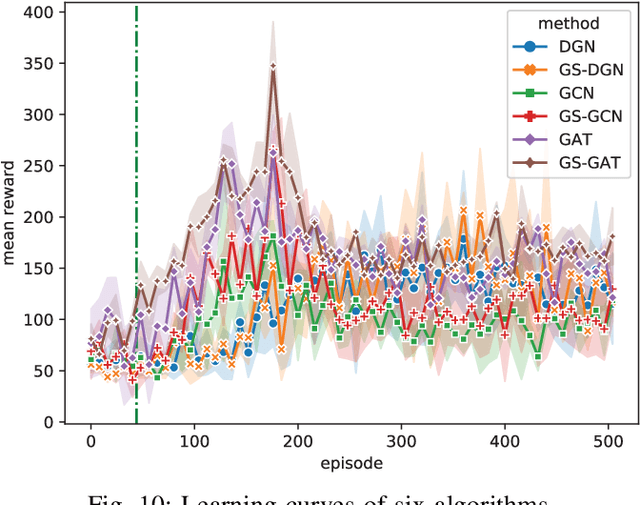
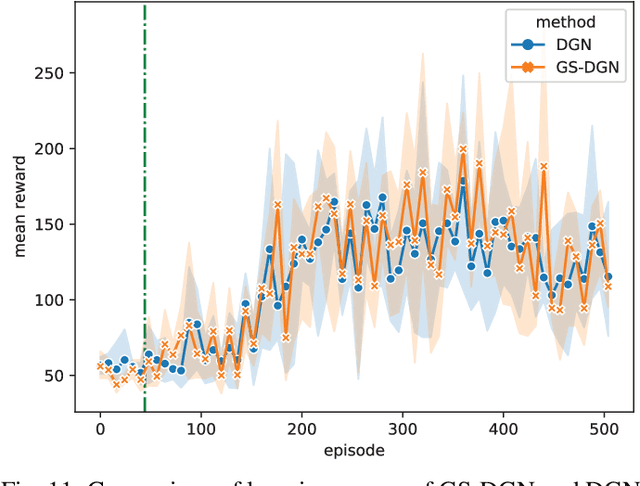
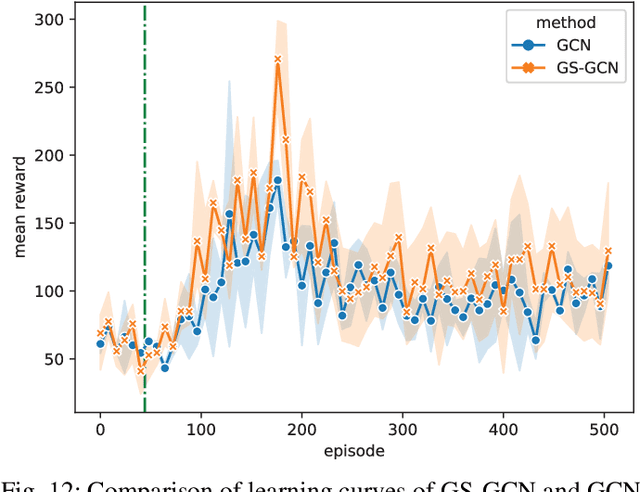
Vital importance has necessity to be attached to cooperation in multi-agent environments, as a result of which some reinforcement learning algorithms combined with graph neural networks have been proposed to understand the mutual interplay between agents. However, highly complicated and dynamic multi-agent environments require more ingenious graph neural networks, which can comprehensively represent not only the graph topology structure but also evolution process of the structure due to agents emerging, disappearing and moving. To tackle these difficulties, we propose Gumbel Sinkhorn graph attention reinforcement learning, where a graph attention network highly represents the underlying graph topology structure of the multi-agent environment, and can adapt to the dynamic topology structure of graph better with the help of Gumbel Sinkhorn network by learning latent permutations. Empirically, simulation results show how our proposed graph reinforcement learning methodology outperforms existing methods in the PettingZoo multi-agent environment by learning latent permutations.