 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat About Emotions? Guiding Fine-Grained Emotion Extraction from Mobile App Reviews
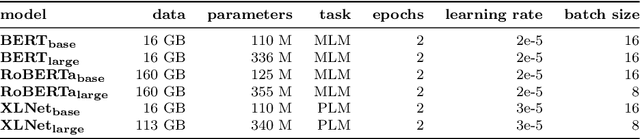
May 29, 2025Opinion mining plays a vital role in analysing user feedback and extracting insights from textual data. While most research focuses on sentiment polarity (e.g., positive, negative, neutral), fine-grained emotion classification in app reviews remains underexplored. This paper addresses this gap by identifying and addressing the challenges and limitations in fine-grained emotion analysis in the context of app reviews. Our study adapts Plutchik's emotion taxonomy to app reviews by developing a structured annotation framework and dataset. Through an iterative human annotation process, we define clear annotation guidelines and document key challenges in emotion classification. Additionally, we evaluate the feasibility of automating emotion annotation using large language models, assessing their cost-effectiveness and agreement with human-labelled data. Our findings reveal that while large language models significantly reduce manual effort and maintain substantial agreement with human annotators, full automation remains challenging due to the complexity of emotional interpretation. This work contributes to opinion mining by providing structured guidelines, an annotated dataset, and insights for developing automated pipelines to capture the complexity of emotions in app reviews.
Leveraging Large Language Models for Mobile App Review Feature Extraction
Aug 02, 2024

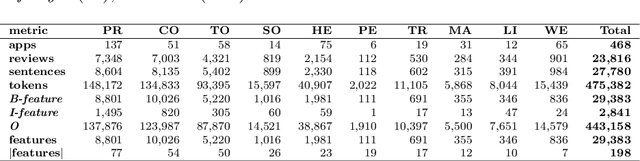
Mobile app review analysis presents unique challenges due to the low quality, subjective bias, and noisy content of user-generated documents. Extracting features from these reviews is essential for tasks such as feature prioritization and sentiment analysis, but it remains a challenging task. Meanwhile, encoder-only models based on the Transformer architecture have shown promising results for classification and information extraction tasks for multiple software engineering processes. This study explores the hypothesis that encoder-only large language models can enhance feature extraction from mobile app reviews. By leveraging crowdsourced annotations from an industrial context, we redefine feature extraction as a supervised token classification task. Our approach includes extending the pre-training of these models with a large corpus of user reviews to improve contextual understanding and employing instance selection techniques to optimize model fine-tuning. Empirical evaluations demonstrate that this method improves the precision and recall of extracted features and enhances performance efficiency. Key contributions include a novel approach to feature extraction, annotated datasets, extended pre-trained models, and an instance selection mechanism for cost-effective fine-tuning. This research provides practical methods and empirical evidence in applying large language models to natural language processing tasks within mobile app reviews, offering improved performance in feature extraction.
Conversational Agents in Software Engineering: Survey, Taxonomy and Challenges
Jun 21, 2021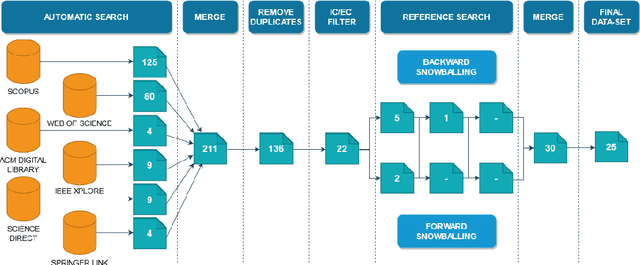
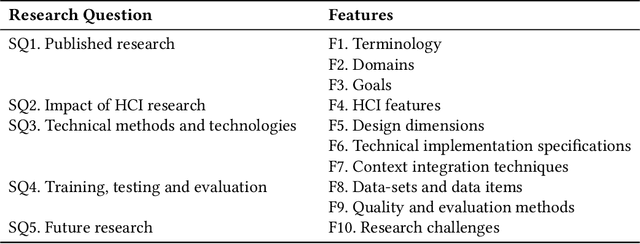
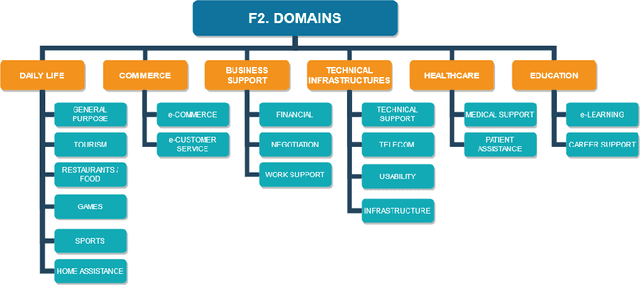
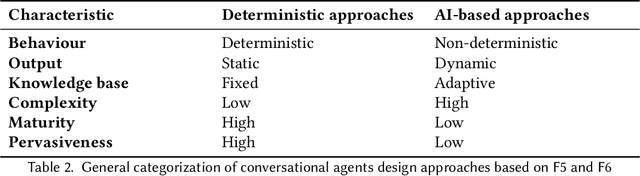
The use of natural language interfaces in the field of human-computer interaction is undergoing intense study through dedicated scientific and industrial research. The latest contributions in the field, including deep learning approaches like recurrent neural networks, the potential of context-aware strategies and user-centred design approaches, have brought back the attention of the community to software-based dialogue systems, generally known as conversational agents or chatbots. Nonetheless, and given the novelty of the field, a generic, context-independent overview on the current state of research of conversational agents covering all research perspectives involved is missing. Motivated by this context, this paper reports a survey of the current state of research of conversational agents through a systematic literature review of secondary studies. The conducted research is designed to develop an exhaustive perspective through a clear presentation of the aggregated knowledge published by recent literature within a variety of domains, research focuses and contexts. As a result, this research proposes a holistic taxonomy of the different dimensions involved in the conversational agents' field, which is expected to help researchers and to lay the groundwork for future research in the field of natural language interfaces.