 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Large Language Models for Mobile App Review Feature Extraction
Paper and Code

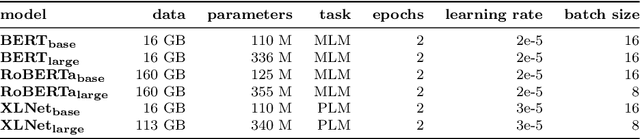

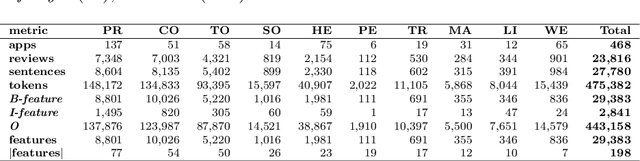
Mobile app review analysis presents unique challenges due to the low quality, subjective bias, and noisy content of user-generated documents. Extracting features from these reviews is essential for tasks such as feature prioritization and sentiment analysis, but it remains a challenging task. Meanwhile, encoder-only models based on the Transformer architecture have shown promising results for classification and information extraction tasks for multiple software engineering processes. This study explores the hypothesis that encoder-only large language models can enhance feature extraction from mobile app reviews. By leveraging crowdsourced annotations from an industrial context, we redefine feature extraction as a supervised token classification task. Our approach includes extending the pre-training of these models with a large corpus of user reviews to improve contextual understanding and employing instance selection techniques to optimize model fine-tuning. Empirical evaluations demonstrate that this method improves the precision and recall of extracted features and enhances performance efficiency. Key contributions include a novel approach to feature extraction, annotated datasets, extended pre-trained models, and an instance selection mechanism for cost-effective fine-tuning. This research provides practical methods and empirical evidence in applying large language models to natural language processing tasks within mobile app reviews, offering improved performance in feature extraction.