 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNARRepair: Non-Autoregressive Code Generation Model for Automatic Program Repair
Jun 24, 2024With the advancement of deep learning techniques, the performance of Automatic Program Repair(APR) techniques has reached a new level. Previous deep learning-based APR techniques essentially modified program sentences in the Autoregressive(AR) manner, which predicts future values based on past values. Due to the manner of word-by-word generation, the AR-based APR technique has a huge time delay. This negative consequence overshadows the widespread adoption of APR techniques in real-life software development. To address the issue, we aim to apply the Non-Autoregressive(NAR) method to the APR task, which can output target code in a parallel manner to avoid huge inference delays. To effectively adapt the NAR manner for the APR task, we in this paper propose NARRepair, the first customized NAR code generation model for the APR task. The NARRepair features three major novelties, including 1) using repair actions to alleviate the over-correction issue, 2) extracting dependency information from AST to alleviate the issue of lacking inter-word dependency information, 3) employing two-stage decoding to alleviate the issue of lacking contextual information. We evaluated NARRepair on three widely used datasets in the APR community, and the results show that our technique can significantly improve the inference speed while maintaining high repair accuracy.
Exploring and Unleashing the Power of Large Language Models in Automated Code Translation
Apr 23, 2024



Code translation tools are developed for automatic source-to-source translation. Although learning-based transpilers have shown impressive enhancement against rule-based counterparts, owing to their task-specific pre-training on extensive monolingual corpora. Their current performance still remains unsatisfactory for practical deployment, and the associated training resources are also prohibitively expensive. LLMs pre-trained on huge amounts of human-written code/text have shown remarkable performance in many code intelligence tasks due to their powerful generality, even without task-specific training. Thus, LLMs can potentially circumvent the above limitations, but they have not been exhaustively explored yet. This paper investigates diverse LLMs and learning-based transpilers for automated code translation tasks, finding that: although certain LLMs have outperformed current transpilers, they still have some accuracy issues, where most of the failures are induced by a lack of comprehension of source programs (38.51%), missing clear instructions on I/O types in translation (14.94%), and ignoring discrepancies between source and target programs (41.38%). Enlightened by the above findings, we propose UniTrans, an Unified code Translation framework, applicable to various LLMs, for unleashing their power in this field. Specifically, UniTrans first craft a series of test cases for target programs with the assistance of source programs. Next, it harnesses the above auto-generated test cases to augment the code translation and then evaluate their correctness via execution. Afterward, UniTrans further (iteratively) repairs incorrectly translated programs prompted by test case execution results. Extensive experiments are conducted on six translation datasets between Python, Java, and C++. Three recent LLMs of diverse sizes are tested with UniTrans, and all achieve substantial improvements.
Learning the Relation between Code Features and Code Transforms with Structured Prediction
Jul 22, 2019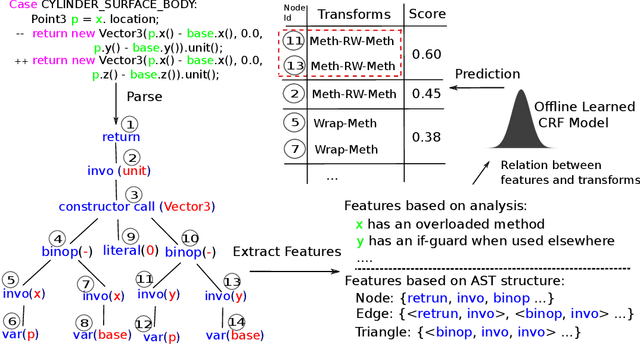
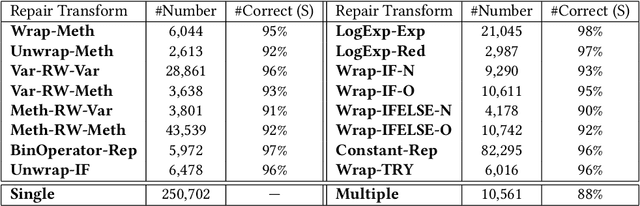
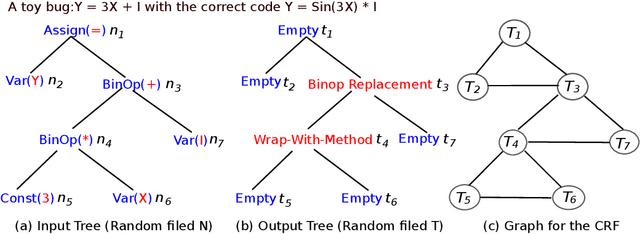
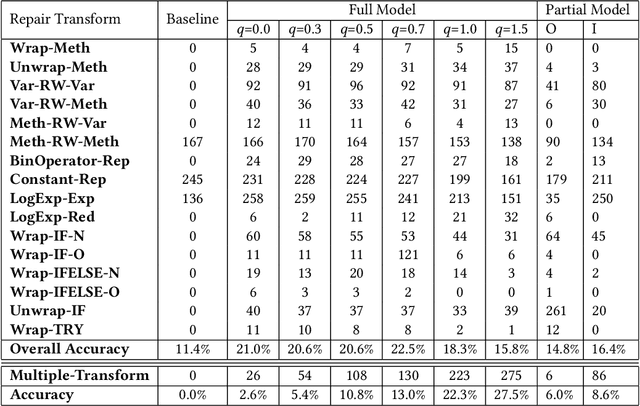
We present in this paper the first approach for structurally predicting code transforms at the level of AST nodes using conditional random fields. Our approach first learns offline a probabilistic model that captures how certain code transforms are applied to certain AST nodes, and then uses the learned model to predict transforms for new, unseen code snippets. We implement our approach in the context of repair transform prediction for Java programs. Our implementation contains a set of carefully designed code features, deals with the training data imbalance issue, and comprises transform constraints that are specific to code. We conduct a large-scale experimental evaluation based on a dataset of 4,590,679 bug fixing commits from real-world Java projects. The experimental results show that our approach predicts the code transforms with a success rate varying from 37.1% to 61.1% depending on the transforms.