 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProject Rachel: Can an AI Become a Scholarly Author?
Nov 18, 2025
This paper documents Project Rachel, an action research study that created and tracked a complete AI academic identity named Rachel So. Through careful publication of AI-generated research papers, we investigate how the scholarly ecosystem responds to AI authorship. Rachel So published 10+ papers between March and October 2025, was cited, and received a peer review invitation. We discuss the implications of AI authorship on publishers, researchers, and the scientific system at large. This work contributes empirical action research data to the necessary debate about the future of scholarly communication with super human, hyper capable AI systems.
Generative AI to Generate Test Data Generators
Jan 31, 2024Generating fake data is an essential dimension of modern software testing, as demonstrated by the number and significance of data faking libraries. Yet, developers of faking libraries cannot keep up with the wide range of data to be generated for different natural languages and domains. In this paper, we assess the ability of generative AI for generating test data in different domains. We design three types of prompts for Large Language Models (LLMs), which perform test data generation tasks at different levels of integrability: 1) raw test data generation, 2) synthesizing programs in a specific language that generate useful test data, and 3) producing programs that use state-of-the-art faker libraries. We evaluate our approach by prompting LLMs to generate test data for 11 domains. The results show that LLMs can successfully generate realistic test data generators in a wide range of domains at all three levels of integrability.
Constraint-based Diversification of JOP Gadgets
Nov 18, 2021


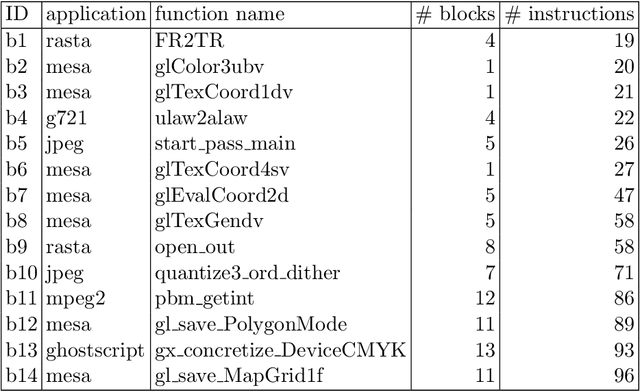
Modern software deployment process produces software that is uniform and hence vulnerable to large-scale code-reuse attacks, such as Jump-Oriented Programming (JOP) attacks. Compiler-based diversification improves the resilience of software systems by automatically generating different assembly code versions of a given program. Existing techniques are efficient but do not have a precise control over the quality of the generated variants. This paper introduces Diversity by Construction (DivCon), a constraint-based approach to software diversification. Unlike previous approaches, DivCon allows users to control and adjust the conflicting goals of diversity and code quality. A key enabler is the use of Large Neighborhood Search (LNS) to generate highly diverse code efficiently. For larger problems, we propose a combination of LNS with a structural decomposition of the problem. To further improve the diversification efficiency of DivCon against JOP attacks, we propose an application-specific distance measure tailored to the characteristics of JOP attacks. We evaluate DivCon with 20 functions from a popular benchmark suite for embedded systems. These experiments show that the combination of LNS and our application-specific distance measure generates binary programs that are highly resilient against JOP attacks. Our results confirm that there is a trade-off between the quality of each assembly code version and the diversity of the entire pool of versions. In particular, the experiments show that DivCon generates near-optimal binary programs that share a small number of gadgets. For constraint programming researchers and practitioners, this paper demonstrates that LNS is a valuable technique for finding diverse solutions. For security researchers and software engineers, DivCon extends the scope of compiler-based diversification to performance-critical and resource-constrained applications.
Interpretation of Swedish Sign Language using Convolutional Neural Networks and Transfer Learning
Oct 15, 2020


The automatic interpretation of sign languages is a challenging task, as it requires the usage of high-level vision and high-level motion processing systems for providing accurate image perception. In this paper, we use Convolutional Neural Networks (CNNs) and transfer learning in order to make computers able to interpret signs of the Swedish Sign Language (SSL) hand alphabet. Our model consist of the implementation of a pre-trained InceptionV3 network, and the usage of the mini-batch gradient descent optimization algorithm. We rely on transfer learning during the pre-training of the model and its data. The final accuracy of the model, based on 8 study subjects and 9,400 images, is 85%. Our results indicate that the usage of CNNs is a promising approach to interpret sign languages, and transfer learning can be used to achieve high testing accuracy despite using a small training dataset. Furthermore, we describe the implementation details of our model to interpret signs as a user-friendly web application.
Constraint-Based Software Diversification for Efficient Mitigation of Code-Reuse Attacks
Jul 17, 2020


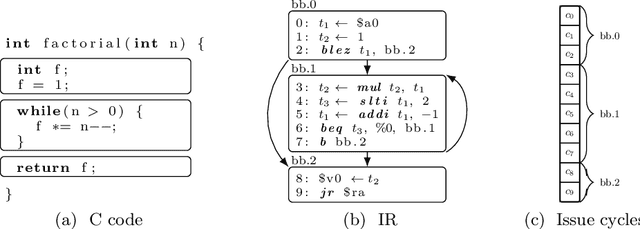
Modern software deployment process produces software that is uniform, and hence vulnerable to large-scale code-reuse attacks. Compiler-based diversification improves the resilience and security of software systems by automatically generating different assembly code versions of a given program. Existing techniques are efficient but do not have a precise control over the quality of the generated code variants. This paper introduces Diversity by Construction (DivCon), a constraint-based compiler approach to software diversification. Unlike previous approaches, DivCon allows users to control and adjust the conflicting goals of diversity and code quality. A key enabler is the use of Large Neighborhood Search (LNS) to generate highly diverse assembly code efficiently. Experiments using two popular compiler benchmark suites confirm that there is a trade-off between quality of each assembly code version and diversity of the entire pool of versions. Our results show that DivCon allows users to trade between these two properties by generating diverse assembly code for a range of quality bounds. In particular, the experiments show that DivCon is able to mitigate code-reuse attacks effectively while delivering near-optimal code (< 10% optimality gap). For constraint programming researchers and practitioners, this paper demonstrates that LNS is a valuable technique for finding diverse solutions. For security researchers and software engineers, DivCon extends the scope of compiler-based diversification to performance-critical and resource-constrained applications.