 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMDD: a Mask Diffusion Detector to Protect Speaker Verification Systems from Adversarial Perturbations
Aug 26, 2025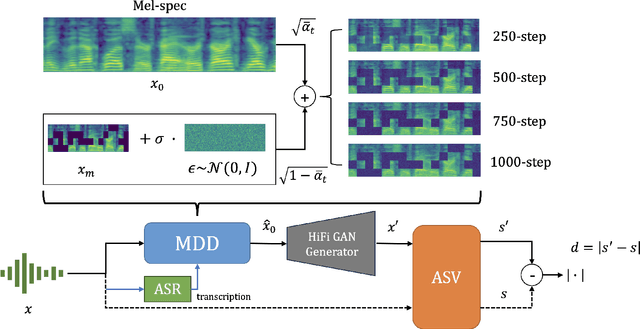
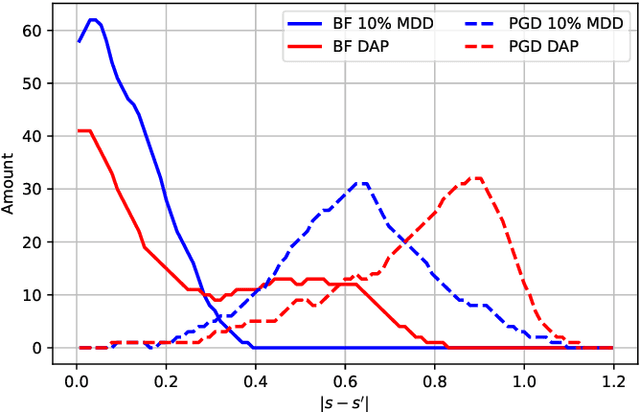
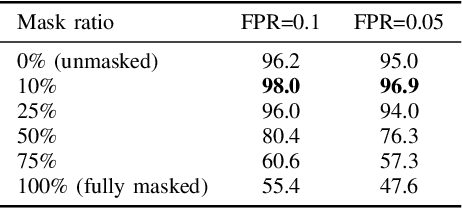

Speaker verification systems are increasingly deployed in security-sensitive applications but remain highly vulnerable to adversarial perturbations. In this work, we propose the Mask Diffusion Detector (MDD), a novel adversarial detection and purification framework based on a \textit{text-conditioned masked diffusion model}. During training, MDD applies partial masking to Mel-spectrograms and progressively adds noise through a forward diffusion process, simulating the degradation of clean speech features. A reverse process then reconstructs the clean representation conditioned on the input transcription. Unlike prior approaches, MDD does not require adversarial examples or large-scale pretraining. Experimental results show that MDD achieves strong adversarial detection performance and outperforms prior state-of-the-art methods, including both diffusion-based and neural codec-based approaches. Furthermore, MDD effectively purifies adversarially-manipulated speech, restoring speaker verification performance to levels close to those observed under clean conditions. These findings demonstrate the potential of diffusion-based masking strategies for secure and reliable speaker verification systems.
DualSpec: Text-to-spatial-audio Generation via Dual-Spectrogram Guided Diffusion Model
Feb 26, 2025Text-to-audio (TTA), which generates audio signals from textual descriptions, has received huge attention in recent years. However, recent works focused on text to monaural audio only. As we know, spatial audio provides more immersive auditory experience than monaural audio, e.g. in virtual reality. To address this issue, we propose a text-to-spatial-audio (TTSA) generation framework named DualSpec.Specifically, it first trains variational autoencoders (VAEs) for extracting the latent acoustic representations from sound event audio. Then, given text that describes sound events and event directions, the proposed method uses the encoder of a pretrained large language model to transform the text into text features. Finally, it trains a diffusion model from the latent acoustic representations and text features for the spatial audio generation. In the inference stage, only the text description is needed to generate spatial audio. Particularly, to improve the synthesis quality and azimuth accuracy of the spatial sound events simultaneously, we propose to use two kinds of acoustic features. One is the Mel spectrograms which is good for improving the synthesis quality, and the other is the short-time Fourier transform spectrograms which is good at improving the azimuth accuracy. We provide a pipeline of constructing spatial audio dataset with text prompts, for the training of the VAEs and diffusion model. We also introduce new spatial-aware evaluation metrics to quantify the azimuth errors of the generated spatial audio recordings. Experimental results demonstrate that the proposed method can generate spatial audio with high directional and event consistency.
Bridging the Gap between Text, Audio, Image, and Any Sequence: A Novel Approach using Gloss-based Annotation
Oct 04, 2024



This paper presents an innovative approach called BGTAI to simplify multimodal understanding by utilizing gloss-based annotation as an intermediate step in aligning Text and Audio with Images. While the dynamic temporal factors in textual and audio inputs contain various predicate adjectives that influence the meaning of the entire sentence, images, on the other hand, present static scenes. By representing text and audio as gloss notations that omit complex semantic nuances, a better alignment with images can potentially be achieved. This study explores the feasibility of this idea, specifically, we first propose the first Langue2Gloss model and then integrate it into the multimodal model UniBriVL for joint training. To strengthen the adaptability of gloss with text/audio and overcome the efficiency and instability issues in multimodal training, we propose a DS-Net (Data-Pair Selection Network), an Result Filter module, and a novel SP-Loss function. Our approach outperforms previous multimodal models in the main experiments, demonstrating its efficacy in enhancing multimodal representations and improving compatibility among text, audio, visual, and any sequence modalities.
Echotune: A Modular Extractor Leveraging the Variable-Length Nature of Speech in ASR Tasks
Sep 14, 2023The Transformer architecture has proven to be highly effective for Automatic Speech Recognition (ASR) tasks, becoming a foundational component for a plethora of research in the domain. Historically, many approaches have leaned on fixed-length attention windows, which becomes problematic for varied speech samples in duration and complexity, leading to data over-smoothing and neglect of essential long-term connectivity. Addressing this limitation, we introduce Echo-MSA, a nimble module equipped with a variable-length attention mechanism that accommodates a range of speech sample complexities and durations. This module offers the flexibility to extract speech features across various granularities, spanning from frames and phonemes to words and discourse. The proposed design captures the variable length feature of speech and addresses the limitations of fixed-length attention. Our evaluation leverages a parallel attention architecture complemented by a dynamic gating mechanism that amalgamates traditional attention with the Echo-MSA module output. Empirical evidence from our study reveals that integrating Echo-MSA into the primary model's training regime significantly enhances the word error rate (WER) performance, all while preserving the intrinsic stability of the original model.