 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonolingual or Multilingual Instruction Tuning: Which Makes a Better Alpaca
Paper and Code
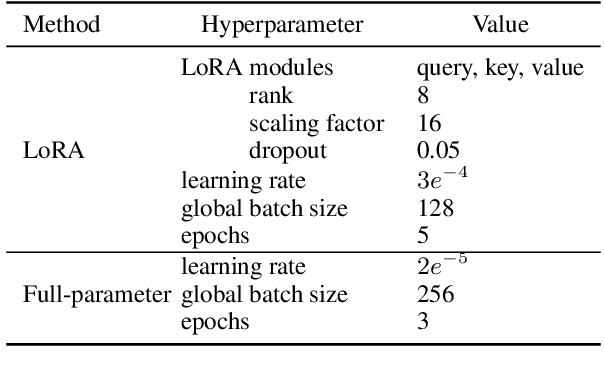

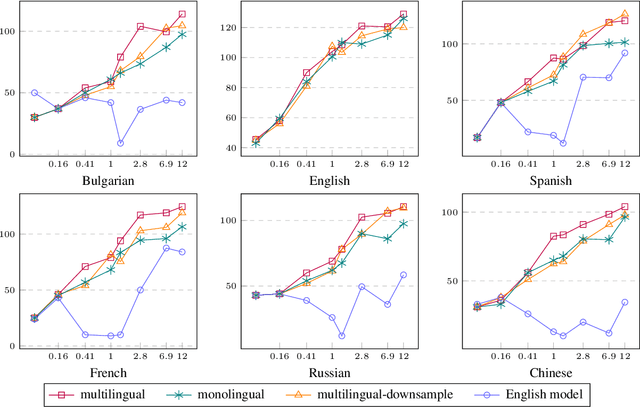
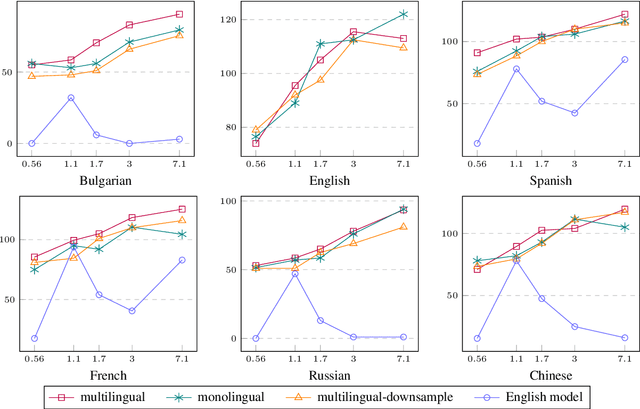
Foundational large language models (LLMs) can be instruction-tuned to develop open-ended question-answering capability, facilitating applications such as the creation of AI assistants. While such efforts are often carried out in a single language, building on prior research, we empirically analyze cost-efficient approaches of monolingual and multilingual tuning, shedding light on the efficacy of LLMs in responding to queries across monolingual and multilingual contexts. Our study employs the Alpaca dataset and machine translations of it to form multilingual training data, which is then used to tune LLMs through low-rank adaptation and full-parameter training. Comparisons reveal that multilingual tuning is not crucial for an LLM's English performance, but is key to its robustness in a multilingual environment. With a fixed budget, a multilingual instruction-tuned model, merely trained on downsampled data, can be as powerful as training monolingual models for each language. Our findings serve as a guide for expanding language support through instruction tuning with constrained computational resources.