 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning and Regret Bounds for Admission Control
Jun 07, 2024The expected regret of any reinforcement learning algorithm is lower bounded by $\Omega\left(\sqrt{DXAT}\right)$ for undiscounted returns, where $D$ is the diameter of the Markov decision process, $X$ the size of the state space, $A$ the size of the action space and $T$ the number of time steps. However, this lower bound is general. A smaller regret can be obtained by taking into account some specific knowledge of the problem structure. In this article, we consider an admission control problem to an $M/M/c/S$ queue with $m$ job classes and class-dependent rewards and holding costs. Queuing systems often have a diameter that is exponential in the buffer size $S$, making the previous lower bound prohibitive for any practical use. We propose an algorithm inspired by UCRL2, and use the structure of the problem to upper bound the expected total regret by $O(S\log T + \sqrt{mT \log T})$ in the finite server case. In the infinite server case, we prove that the dependence of the regret on $S$ disappears.
A unified framework for coordination of thermostatically controlled loads
Aug 12, 2021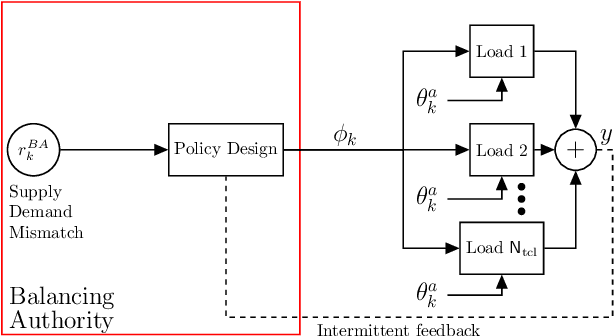
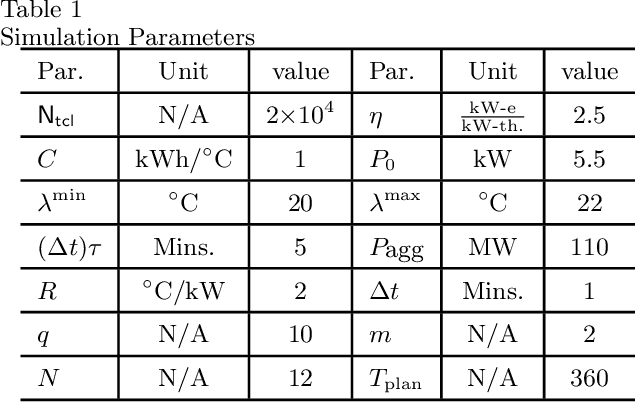
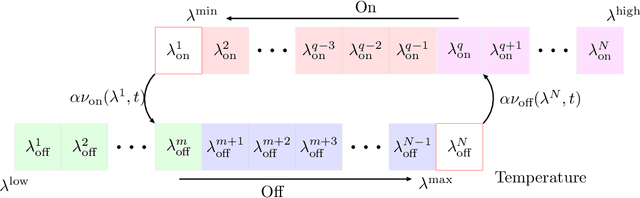
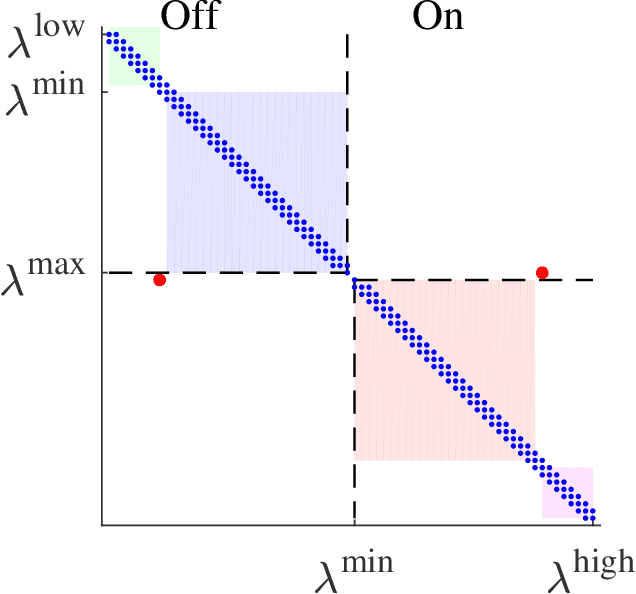
A collection of thermostatically controlled loads (TCLs) -- such as air conditioners and water heaters -- can vary their power consumption within limits to help the balancing authority of a power grid maintain demand supply balance. Doing so requires loads to coordinate their on/off decisions so that the aggregate power consumption profile tracks a grid-supplied reference. At the same time, each consumer's quality of service (QoS) must be maintained. While there is a large body of work on TCL coordination, there are several limitations. One is that they do not provide guarantees on the reference tracking performance and QoS maintenance. A second limitation of past work is that they do not provide a means to compute a suitable reference signal for power demand of a collection of TCLs. In this work we provide a framework that addresses these weaknesses. The framework enables coordination of an arbitrary number of TCLs that: (i) is computationally efficient, (ii) is implementable at the TCLs with local feedback and low communication, and (iii) enables reference tracking by the collection while ensuring that temperature and cycling constraints are satisfied at every TCL at all times. The framework is based on a Markov model obtained by discretizing a pair of Fokker-Planck equations derived in earlier work by Malhame and Chong [21]. We then use this model to design randomized policies for TCLs. The balancing authority broadcasts the same policy to all TCLs, and each TCL implements this policy which requires only local measurement to make on/off decisions. Simulation results are provided to support these claims.
Explicit Mean-Square Error Bounds for Monte-Carlo and Linear Stochastic Approximation
Feb 07, 2020This paper concerns error bounds for recursive equations subject to Markovian disturbances. Motivating examples abound within the fields of Markov chain Monte Carlo (MCMC) and Reinforcement Learning (RL), and many of these algorithms can be interpreted as special cases of stochastic approximation (SA). It is argued that it is not possible in general to obtain a Hoeffding bound on the error sequence, even when the underlying Markov chain is reversible and geometrically ergodic, such as the M/M/1 queue. This is motivation for the focus on mean square error bounds for parameter estimates. It is shown that mean square error achieves the optimal rate of $O(1/n)$, subject to conditions on the step-size sequence. Moreover, the exact constants in the rate are obtained, which is of great value in algorithm design.
Zap Q-Learning With Nonlinear Function Approximation
Oct 11, 2019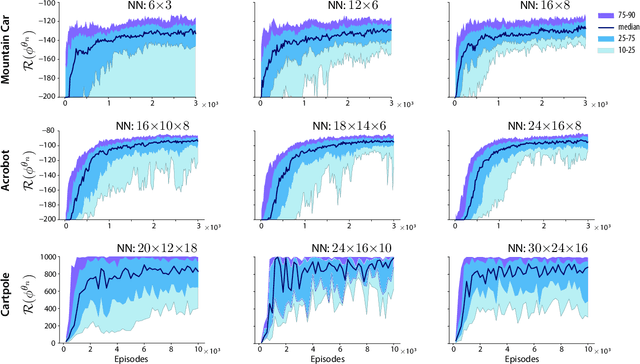
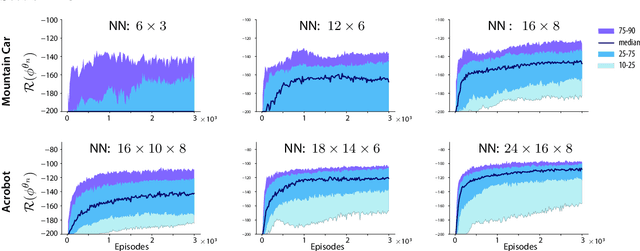
The Zap stochastic approximation (SA) algorithm was introduced recently as a means to accelerate convergence in reinforcement learning algorithms. While numerical results were impressive, stability (in the sense of boundedness of parameter estimates) was established in only a few special cases. This class of algorithms is generalized in this paper, and stability is established under very general conditions. This general result can be applied to a wide range of algorithms found in reinforcement learning. Two classes are considered in this paper: (i)The natural generalization of Watkins' algorithm is not always stable in function approximation settings. Parameter estimates may diverge to infinity even in the \textit{linear} function approximation setting with a simple finite state-action MDP. Under mild conditions, the Zap SA algorithm provides a stable algorithm, even in the case of \textit{nonlinear} function approximation. (ii) The GQ algorithm of Maei et.~al.~2010 is designed to address the stability challenge. Analysis is provided to explain why the algorithm may be very slow to converge in practice. The new Zap GQ algorithm is stable even for nonlinear function approximation.
Zap Q-Learning for Optimal Stopping Time Problems
May 01, 2019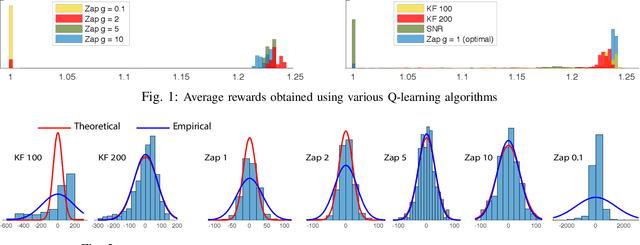
We propose a novel reinforcement learning algorithm that approximates solutions to the problem of discounted optimal stopping in an irreducible, uniformly ergodic Markov chain evolving on a compact subset of $\mathbb R^n$. A dynamic programming approach has been taken by Tsitsikilis and Van Roy to solve this problem, wherein they propose a Q-learning algorithm to estimate the value function, in a linear function approximation setting. The Zap-Q learning algorithm proposed in this work is the first algorithm that is designed to achieve optimal asymptotic variance. We prove convergence of the algorithm using ODE analysis, and the optimal asymptotic variance property is reflected via fast convergence in a finance example.
Zap Meets Momentum: Stochastic Approximation Algorithms with Optimal Convergence Rate
Sep 17, 2018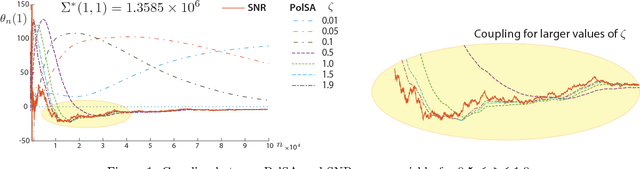
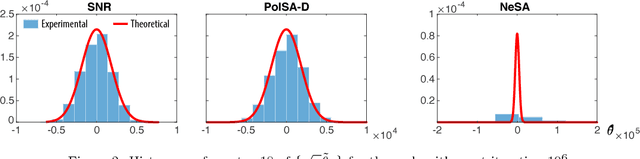
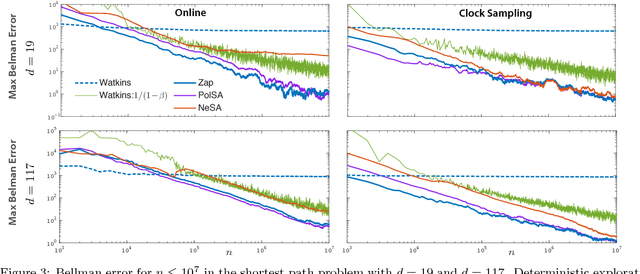
There are two well known Stochastic Approximation techniques that are known to have optimal rate of convergence (measured in terms of asymptotic variance): the Ruppert-Polyak averaging technique, and stochastic Newton-Raphson (SNR) (a matrix gain algorithm that resembles the deterministic Newton-Raphson method). The Zap algorithms introduced by the authors are a version of SNR designed to behave more closely like their deterministic cousin. It is found that estimates from the Zap Q-learning algorithm converge remarkably quickly, but the per-iteration complexity can be high. This paper introduces an entirely new class of stochastic approximation algorithms based on matrix momentum. For a special choice of the matrix momentum and gain sequences, it is found in simulations that the parameter estimates obtained from the algorithm couple with those obtained from the more complex stochastic Newton-Raphson algorithm. Conditions under which coupling is guaranteed are established for a class of linear recursions. Optimal finite-$n$ error bounds are also obtained. The main objective of this work is to create more efficient algorithms for applications to reinforcement learning. Numerical results illustrate the value of these techniques in this setting.