 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQVD: Post-training Quantization for Video Diffusion Models
Jul 16, 2024Recently, video diffusion models (VDMs) have garnered significant attention due to their notable advancements in generating coherent and realistic video content. However, processing multiple frame features concurrently, coupled with the considerable model size, results in high latency and extensive memory consumption, hindering their broader application. Post-training quantization (PTQ) is an effective technique to reduce memory footprint and improve computational efficiency. Unlike image diffusion, we observe that the temporal features, which are integrated into all frame features, exhibit pronounced skewness. Furthermore, we investigate significant inter-channel disparities and asymmetries in the activation of video diffusion models, resulting in low coverage of quantization levels by individual channels and increasing the challenge of quantization. To address these issues, we introduce the first PTQ strategy tailored for video diffusion models, dubbed QVD. Specifically, we propose the High Temporal Discriminability Quantization (HTDQ) method, designed for temporal features, which retains the high discriminability of quantized features, providing precise temporal guidance for all video frames. In addition, we present the Scattered Channel Range Integration (SCRI) method which aims to improve the coverage of quantization levels across individual channels. Experimental validations across various models, datasets, and bit-width settings demonstrate the effectiveness of our QVD in terms of diverse metrics. In particular, we achieve near-lossless performance degradation on W8A8, outperforming the current methods by 205.12 in FVD.
Decision Fusion Network with Perception Fine-tuning for Defect Classification
Sep 22, 2023
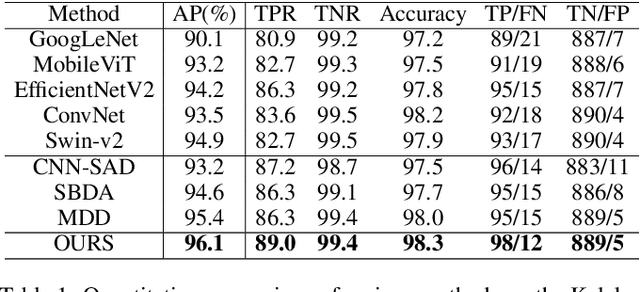
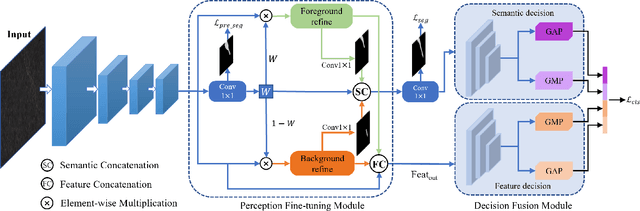
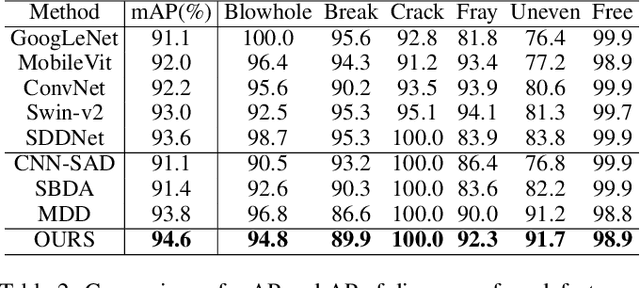
Surface defect inspection is an important task in industrial inspection. Deep learning-based methods have demonstrated promising performance in this domain. Nevertheless, these methods still suffer from misjudgment when encountering challenges such as low-contrast defects and complex backgrounds. To overcome these issues, we present a decision fusion network (DFNet) that incorporates the semantic decision with the feature decision to strengthen the decision ability of the network. In particular, we introduce a decision fusion module (DFM) that extracts a semantic vector from the semantic decision branch and a feature vector for the feature decision branch and fuses them to make the final classification decision. In addition, we propose a perception fine-tuning module (PFM) that fine-tunes the foreground and background during the segmentation stage. PFM generates the semantic and feature outputs that are sent to the classification decision stage. Furthermore, we present an inner-outer separation weight matrix to address the impact of label edge uncertainty during segmentation supervision. Our experimental results on the publicly available datasets including KolektorSDD2 (96.1% AP) and Magnetic-tile-defect-datasets (94.6% mAP) demonstrate the effectiveness of the proposed method.