 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Implicit Transporter for Temporally Consistent Keypoint Discovery
Sep 10, 2023



Keypoint-based representation has proven advantageous in various visual and robotic tasks. However, the existing 2D and 3D methods for detecting keypoints mainly rely on geometric consistency to achieve spatial alignment, neglecting temporal consistency. To address this issue, the Transporter method was introduced for 2D data, which reconstructs the target frame from the source frame to incorporate both spatial and temporal information. However, the direct application of the Transporter to 3D point clouds is infeasible due to their structural differences from 2D images. Thus, we propose the first 3D version of the Transporter, which leverages hybrid 3D representation, cross attention, and implicit reconstruction. We apply this new learning system on 3D articulated objects and nonrigid animals (humans and rodents) and show that learned keypoints are spatio-temporally consistent. Additionally, we propose a closed-loop control strategy that utilizes the learned keypoints for 3D object manipulation and demonstrate its superior performance. Codes are available at https://github.com/zhongcl-thu/3D-Implicit-Transporter.
SNAKE: Shape-aware Neural 3D Keypoint Field
Jun 03, 2022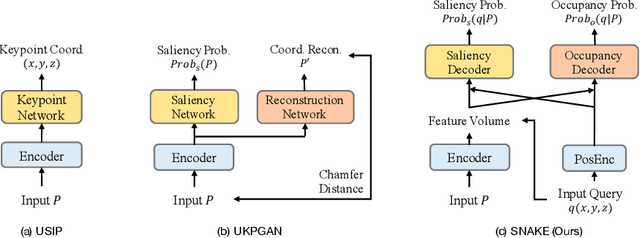
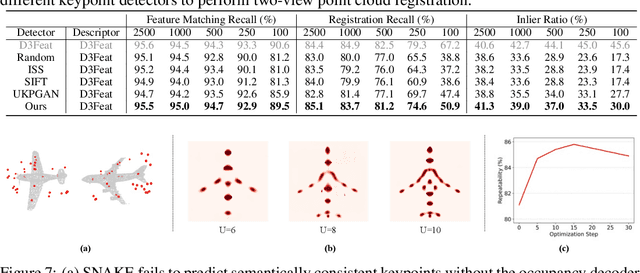
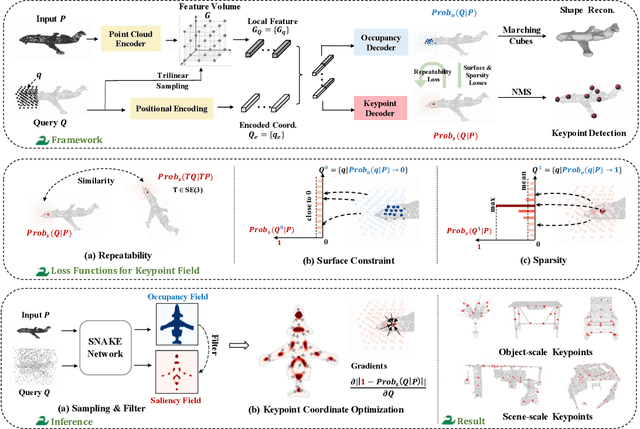
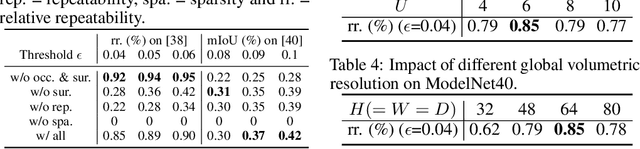
Detecting 3D keypoints from point clouds is important for shape reconstruction, while this work investigates the dual question: can shape reconstruction benefit 3D keypoint detection? Existing methods either seek salient features according to statistics of different orders or learn to predict keypoints that are invariant to transformation. Nevertheless, the idea of incorporating shape reconstruction into 3D keypoint detection is under-explored. We argue that this is restricted by former problem formulations. To this end, a novel unsupervised paradigm named SNAKE is proposed, which is short for shape-aware neural 3D keypoint field. Similar to recent coordinate-based radiance or distance field, our network takes 3D coordinates as inputs and predicts implicit shape indicators and keypoint saliency simultaneously, thus naturally entangling 3D keypoint detection and shape reconstruction. We achieve superior performance on various public benchmarks, including standalone object datasets ModelNet40, KeypointNet, SMPL meshes and scene-level datasets 3DMatch and Redwood. Intrinsic shape awareness brings several advantages as follows. (1) SNAKE generates 3D keypoints consistent with human semantic annotation, even without such supervision. (2) SNAKE outperforms counterparts in terms of repeatability, especially when the input point clouds are down-sampled. (3) the generated keypoints allow accurate geometric registration, notably in a zero-shot setting. Codes are available at https://github.com/zhongcl-thu/SNAKE
Sim2Real Object-Centric Keypoint Detection and Description
Feb 03, 2022


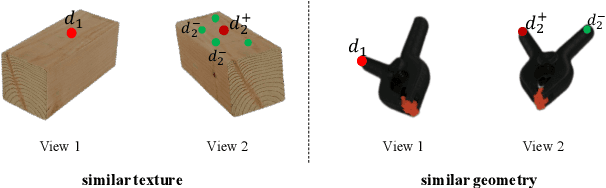
Keypoint detection and description play a central role in computer vision. Most existing methods are in the form of scene-level prediction, without returning the object classes of different keypoints. In this paper, we propose the object-centric formulation, which, beyond the conventional setting, requires further identifying which object each interest point belongs to. With such fine-grained information, our framework enables more downstream potentials, such as object-level matching and pose estimation in a clustered environment. To get around the difficulty of label collection in the real world, we develop a sim2real contrastive learning mechanism that can generalize the model trained in simulation to real-world applications. The novelties of our training method are three-fold: (i) we integrate the uncertainty into the learning framework to improve feature description of hard cases, e.g., less-textured or symmetric patches; (ii) we decouple the object descriptor into two output branches -- intra-object salience and inter-object distinctness, resulting in a better pixel-wise description; (iii) we enforce cross-view semantic consistency for enhanced robustness in representation learning. Comprehensive experiments on image matching and 6D pose estimation verify the encouraging generalization ability of our method from simulation to reality. Particularly for 6D pose estimation, our method significantly outperforms typical unsupervised/sim2real methods, achieving a closer gap with the fully supervised counterpart. Additional results and videos can be found at https://zhongcl-thu.github.io/rock/