 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSim2Real Object-Centric Keypoint Detection and Description
Paper and Code



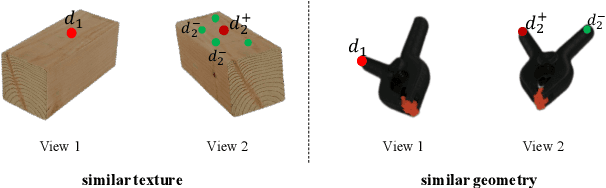
Keypoint detection and description play a central role in computer vision. Most existing methods are in the form of scene-level prediction, without returning the object classes of different keypoints. In this paper, we propose the object-centric formulation, which, beyond the conventional setting, requires further identifying which object each interest point belongs to. With such fine-grained information, our framework enables more downstream potentials, such as object-level matching and pose estimation in a clustered environment. To get around the difficulty of label collection in the real world, we develop a sim2real contrastive learning mechanism that can generalize the model trained in simulation to real-world applications. The novelties of our training method are three-fold: (i) we integrate the uncertainty into the learning framework to improve feature description of hard cases, e.g., less-textured or symmetric patches; (ii) we decouple the object descriptor into two output branches -- intra-object salience and inter-object distinctness, resulting in a better pixel-wise description; (iii) we enforce cross-view semantic consistency for enhanced robustness in representation learning. Comprehensive experiments on image matching and 6D pose estimation verify the encouraging generalization ability of our method from simulation to reality. Particularly for 6D pose estimation, our method significantly outperforms typical unsupervised/sim2real methods, achieving a closer gap with the fully supervised counterpart. Additional results and videos can be found at https://zhongcl-thu.github.io/rock/