 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effect of Compression Techniques on Large Multimodal Language Models in the Medical Domain
Jul 29, 2025Multimodal Large Language Models (MLLMs) hold huge potential for usage in the medical domain, but their computational costs necessitate efficient compression techniques. This paper evaluates the impact of structural pruning and activation-aware quantization on a fine-tuned LLAVA model for medical applications. We propose a novel layer selection method for pruning, analyze different quantization techniques, and assess the performance trade-offs in a prune-SFT-quantize pipeline. Our proposed method enables MLLMs with 7B parameters to run within 4 GB of VRAM, reducing memory usage by 70% while achieving 4% higher model performance compared to traditional pruning and quantization techniques in the same compression ratio.
Lung-Originated Tumor Segmentation from Computed Tomography Scan (LOTUS) Benchmark
Jan 03, 2022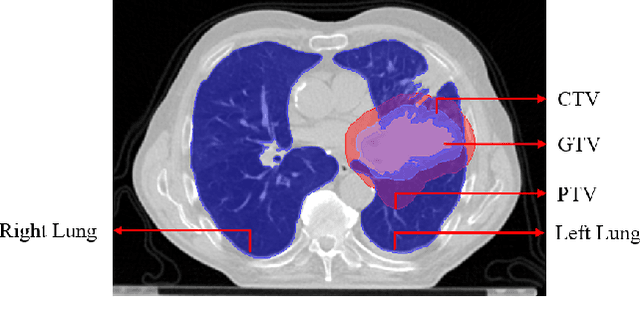
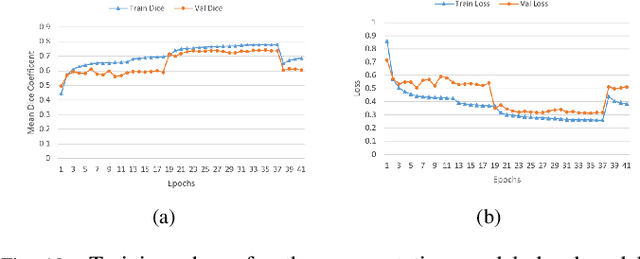
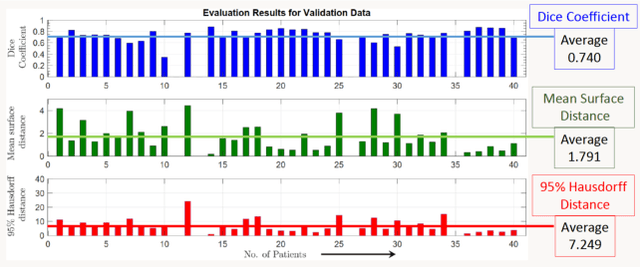
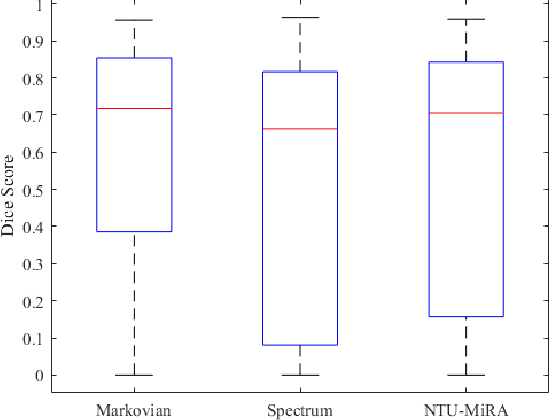
Lung cancer is one of the deadliest cancers, and in part its effective diagnosis and treatment depend on the accurate delineation of the tumor. Human-centered segmentation, which is currently the most common approach, is subject to inter-observer variability, and is also time-consuming, considering the fact that only experts are capable of providing annotations. Automatic and semi-automatic tumor segmentation methods have recently shown promising results. However, as different researchers have validated their algorithms using various datasets and performance metrics, reliably evaluating these methods is still an open challenge. The goal of the Lung-Originated Tumor Segmentation from Computed Tomography Scan (LOTUS) Benchmark created through 2018 IEEE Video and Image Processing (VIP) Cup competition, is to provide a unique dataset and pre-defined metrics, so that different researchers can develop and evaluate their methods in a unified fashion. The 2018 VIP Cup started with a global engagement from 42 countries to access the competition data. At the registration stage, there were 129 members clustered into 28 teams from 10 countries, out of which 9 teams made it to the final stage and 6 teams successfully completed all the required tasks. In a nutshell, all the algorithms proposed during the competition, are based on deep learning models combined with a false positive reduction technique. Methods developed by the three finalists show promising results in tumor segmentation, however, more effort should be put into reducing the false positive rate. This competition manuscript presents an overview of the VIP-Cup challenge, along with the proposed algorithms and results.
Location Forensics of Media Recordings Utilizing Cascaded SVM and Pole-matching Classifiers
Dec 01, 2019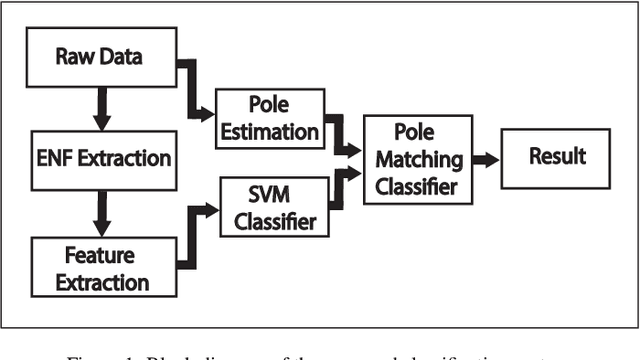
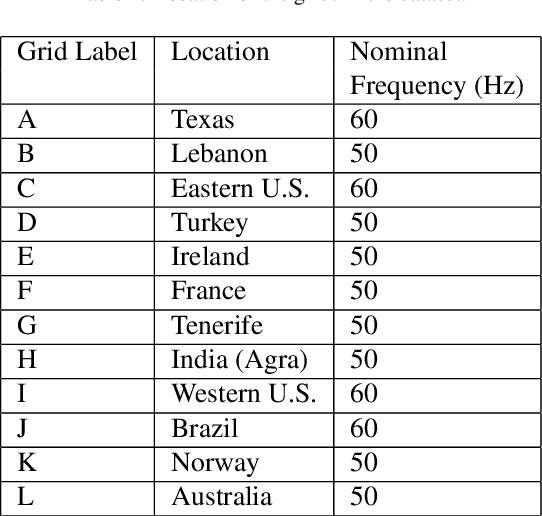


Information regarding the location of power distribution grid can be extracted from the power signature embedded in the multimedia signals (e.g., audio, video data) recorded near electrical activities. This implicit mechanism of identifying the origin-of-recording can be a very promising tool for multimedia forensics and security applications. In this work, we have developed a novel grid-of-origin identification system from media recording that consists of a number of support vector machine (SVM) followed by pole-matching (PM) classifiers. First, we determine the nominal frequency of the grid (50 or 60 Hz) based on the spectral observation. Then an SVM classifier, trained for the detection of a grid with a particular nominal frequency, narrows down the list of possible grids on the basis of different discriminating features extracted from the electric network frequency (ENF) signal. The decision of the SVM classifier is then passed to the PM classifier that detects the final grid based on the minimum distance between the estimated poles of test and training grids. Thus, we start from the problem of classifying grids with different nominal frequencies and simplify the problem of classification in three stages based on nominal frequency, SVM and finally using PM classifier. This cascaded system of classification ensures better accuracy (15.57% higher) compared to traditional ENF-based SVM classifiers described in the literature.
An Ensemble SVM-based Approach for Voice Activity Detection
Feb 05, 2019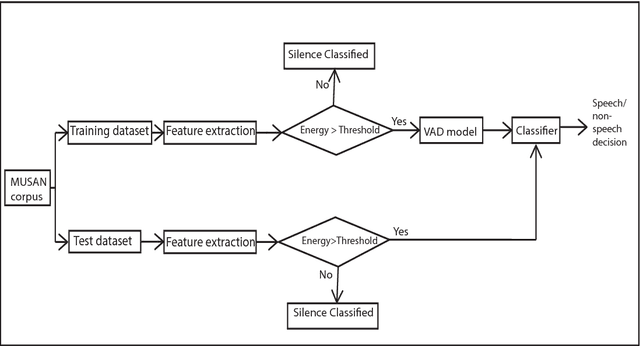
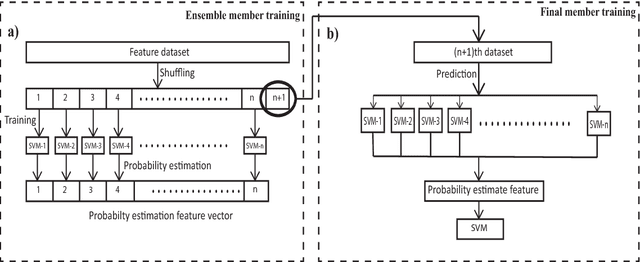
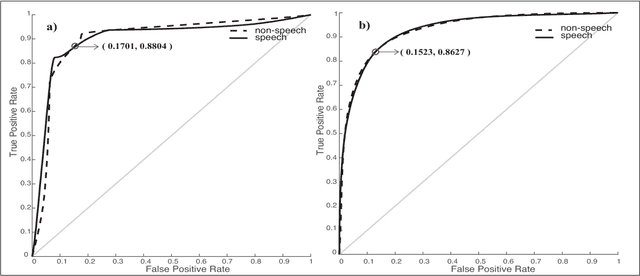

Voice activity detection (VAD), used as the front end of speech enhancement, speech and speaker recognition algorithms, determines the overall accuracy and efficiency of the algorithms. Therefore, a VAD with low complexity and high accuracy is highly desirable for speech processing applications. In this paper, we propose a novel training method on large dataset for supervised learning-based VAD system using support vector machine (SVM). Despite of high classification accuracy of support vector machines (SVM), trivial SVM is not suitable for classification of large data sets needed for a good VAD system because of high training complexity. To overcome this problem, a novel ensemble-based approach using SVM has been proposed in this paper.The performance of the proposed ensemble structure has been compared with a feedforward neural network (NN). Although NN performs better than single SVM-based VAD trained on a small portion of the training data, ensemble SVM gives accuracy comparable to neural network-based VAD. Ensemble SVM and NN give 88.74% and 86.28% accuracy respectively whereas the stand-alone SVM shows 57.05% accuracy on average on the test dataset.
SwishNet: A Fast Convolutional Neural Network for Speech, Music and Noise Classification and Segmentation
Dec 01, 2018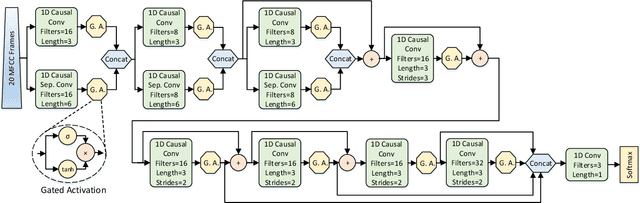
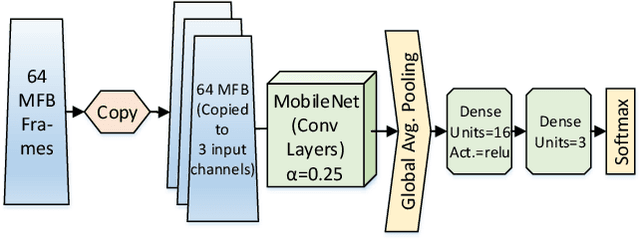
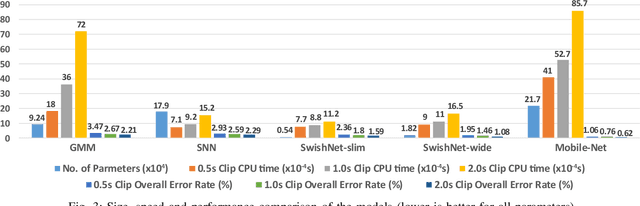
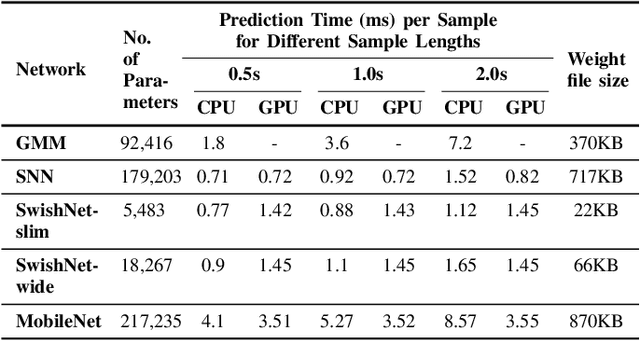
Speech, Music and Noise classification/segmentation is an important preprocessing step for audio processing/indexing. To this end, we propose a novel 1D Convolutional Neural Network (CNN) - SwishNet. It is a fast and lightweight architecture that operates on MFCC features which is suitable to be added to the front-end of an audio processing pipeline. We showed that the performance of our network can be improved by distilling knowledge from a 2D CNN, pretrained on ImageNet. We investigated the performance of our network on the MUSAN corpus - an openly available comprehensive collection of noise, music and speech samples, suitable for deep learning. The proposed network achieved high overall accuracy in clip (length of 0.5-2s) classification (>97% accuracy) and frame-wise segmentation (>93% accuracy) tasks with even higher accuracy (>99%) in speech/non-speech discrimination task. To verify the robustness of our model, we trained it on MUSAN and evaluated it on a different corpus - GTZAN and found good accuracy with very little fine-tuning. We also demonstrated that our model is fast on both CPU and GPU, consumes a low amount of memory and is suitable for implementation in embedded systems.
Native Language Identification using i-vector
Nov 09, 2018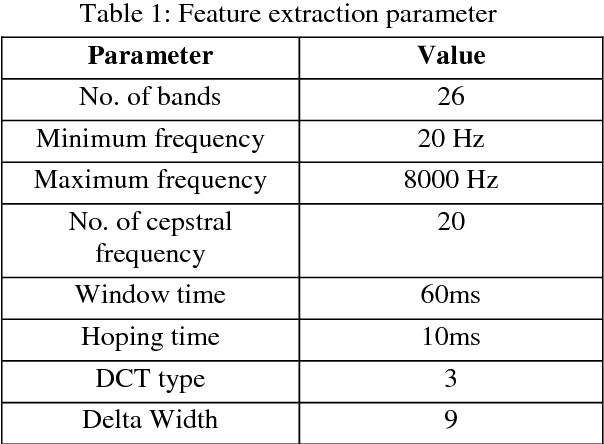
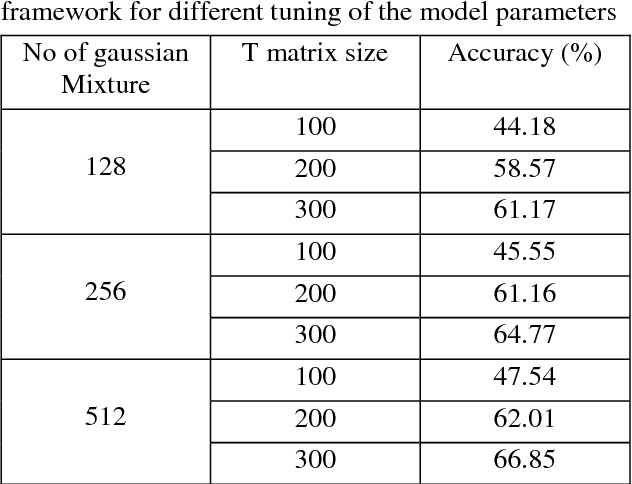
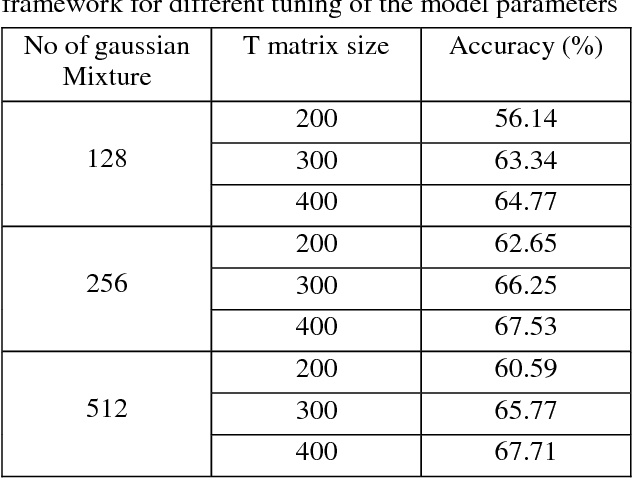
The task of determining a speaker's native language based only on his speeches in a second language is known as Native Language Identification or NLI. Due to its increasing applications in various domains of speech signal processing, this has emerged as an important research area in recent times. In this paper we have proposed an i-vector based approach to develop an automatic NLI system using MFCC and GFCC features. For evaluation of our approach, we have tested our framework on the 2016 ComParE Native language sub-challenge dataset which has English language speakers from 11 different native language backgrounds. Our proposed method outperforms the baseline system with an improvement in accuracy by 21.95% for the MFCC feature based i-vector framework and 22.81% for the GFCC feature based i-vector framework.