 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNative Language Identification using i-vector
Paper and Code
Nov 09, 2018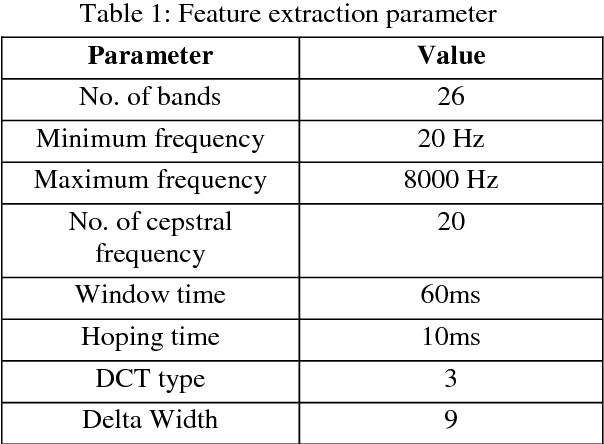
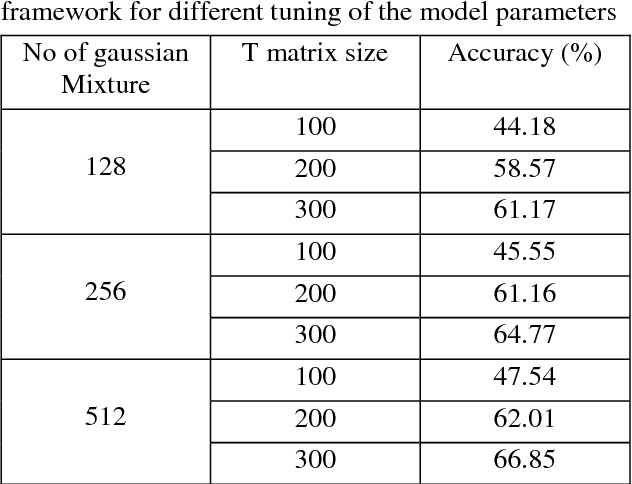
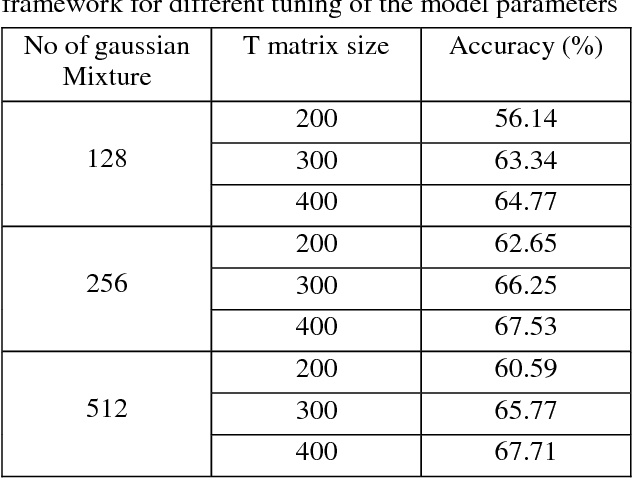
The task of determining a speaker's native language based only on his speeches in a second language is known as Native Language Identification or NLI. Due to its increasing applications in various domains of speech signal processing, this has emerged as an important research area in recent times. In this paper we have proposed an i-vector based approach to develop an automatic NLI system using MFCC and GFCC features. For evaluation of our approach, we have tested our framework on the 2016 ComParE Native language sub-challenge dataset which has English language speakers from 11 different native language backgrounds. Our proposed method outperforms the baseline system with an improvement in accuracy by 21.95% for the MFCC feature based i-vector framework and 22.81% for the GFCC feature based i-vector framework.