 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwishNet: A Fast Convolutional Neural Network for Speech, Music and Noise Classification and Segmentation
Dec 01, 2018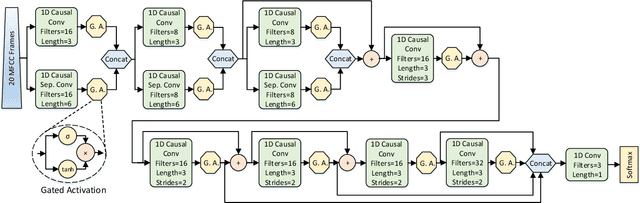
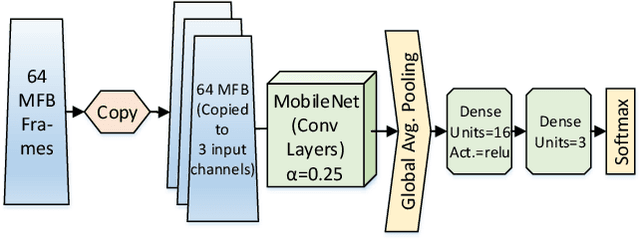
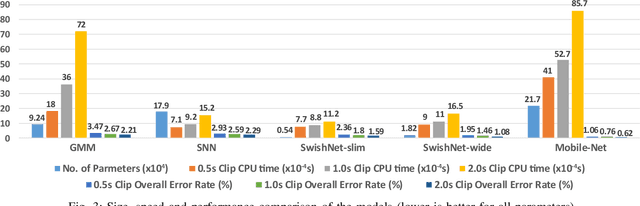
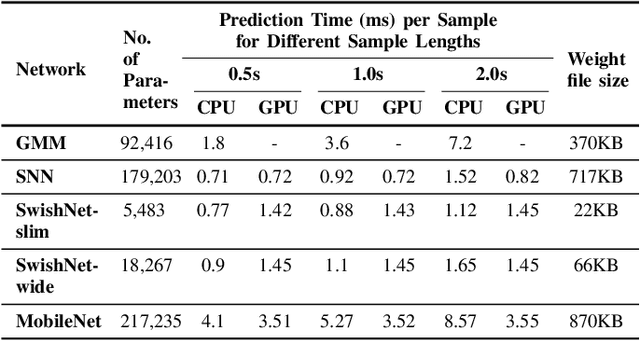
Speech, Music and Noise classification/segmentation is an important preprocessing step for audio processing/indexing. To this end, we propose a novel 1D Convolutional Neural Network (CNN) - SwishNet. It is a fast and lightweight architecture that operates on MFCC features which is suitable to be added to the front-end of an audio processing pipeline. We showed that the performance of our network can be improved by distilling knowledge from a 2D CNN, pretrained on ImageNet. We investigated the performance of our network on the MUSAN corpus - an openly available comprehensive collection of noise, music and speech samples, suitable for deep learning. The proposed network achieved high overall accuracy in clip (length of 0.5-2s) classification (>97% accuracy) and frame-wise segmentation (>93% accuracy) tasks with even higher accuracy (>99%) in speech/non-speech discrimination task. To verify the robustness of our model, we trained it on MUSAN and evaluated it on a different corpus - GTZAN and found good accuracy with very little fine-tuning. We also demonstrated that our model is fast on both CPU and GPU, consumes a low amount of memory and is suitable for implementation in embedded systems.