 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaze-directed Vision GNN for Mitigating Shortcut Learning in Medical Image
Jun 20, 2024



Deep neural networks have demonstrated remarkable performance in medical image analysis. However, its susceptibility to spurious correlations due to shortcut learning raises concerns about network interpretability and reliability. Furthermore, shortcut learning is exacerbated in medical contexts where disease indicators are often subtle and sparse. In this paper, we propose a novel gaze-directed Vision GNN (called GD-ViG) to leverage the visual patterns of radiologists from gaze as expert knowledge, directing the network toward disease-relevant regions, and thereby mitigating shortcut learning. GD-ViG consists of a gaze map generator (GMG) and a gaze-directed classifier (GDC). Combining the global modelling ability of GNNs with the locality of CNNs, GMG generates the gaze map based on radiologists' visual patterns. Notably, it eliminates the need for real gaze data during inference, enhancing the network's practical applicability. Utilizing gaze as the expert knowledge, the GDC directs the construction of graph structures by incorporating both feature distances and gaze distances, enabling the network to focus on disease-relevant foregrounds. Thereby avoiding shortcut learning and improving the network's interpretability. The experiments on two public medical image datasets demonstrate that GD-ViG outperforms the state-of-the-art methods, and effectively mitigates shortcut learning. Our code is available at https://github.com/SX-SS/GD-ViG.
Invariant Content Synergistic Learning for Domain Generalization of Medical Image Segmentation
May 05, 2022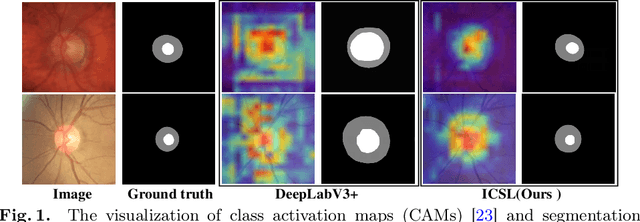
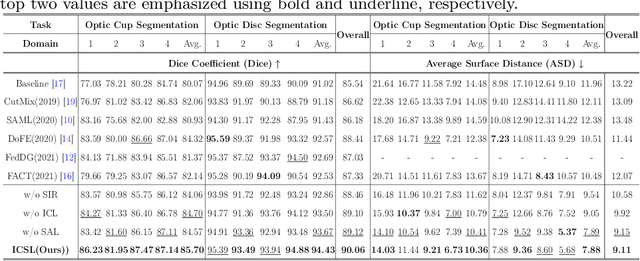
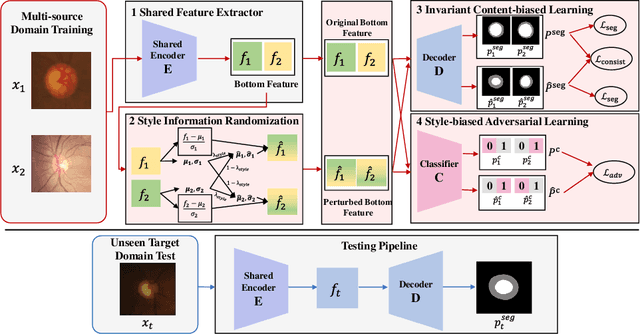
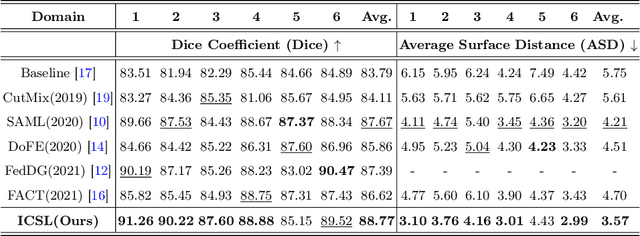
While achieving remarkable success for medical image segmentation, deep convolution neural networks (DCNNs) often fail to maintain their robustness when confronting test data with the novel distribution. To address such a drawback, the inductive bias of DCNNs is recently well-recognized. Specifically, DCNNs exhibit an inductive bias towards image style (e.g., superficial texture) rather than invariant content (e.g., object shapes). In this paper, we propose a method, named Invariant Content Synergistic Learning (ICSL), to improve the generalization ability of DCNNs on unseen datasets by controlling the inductive bias. First, ICSL mixes the style of training instances to perturb the training distribution. That is to say, more diverse domains or styles would be made available for training DCNNs. Based on the perturbed distribution, we carefully design a dual-branches invariant content synergistic learning strategy to prevent style-biased predictions and focus more on the invariant content. Extensive experimental results on two typical medical image segmentation tasks show that our approach performs better than state-of-the-art domain generalization methods.