 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBFA-YOLO: Balanced multiscale object detection network for multi-view building facade attachments detection
Sep 06, 2024

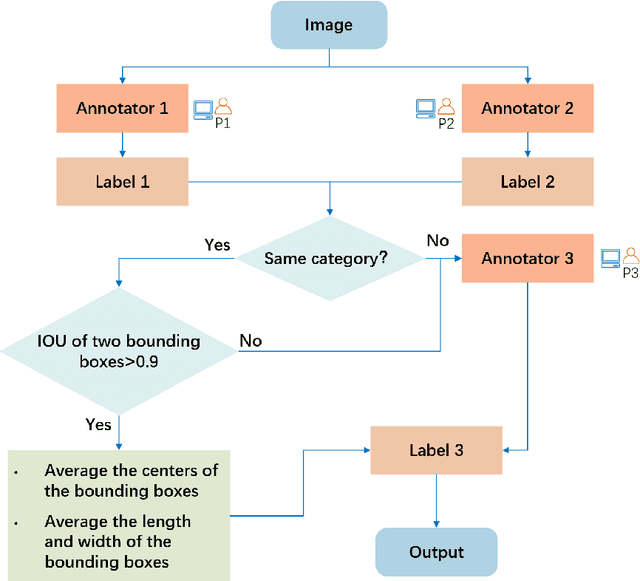

Detection of building facade attachments such as doors, windows, balconies, air conditioner units, billboards, and glass curtain walls plays a pivotal role in numerous applications. Building facade attachments detection aids in vbuilding information modeling (BIM) construction and meeting Level of Detail 3 (LOD3) standards. Yet, it faces challenges like uneven object distribution, small object detection difficulty, and background interference. To counter these, we propose BFA-YOLO, a model for detecting facade attachments in multi-view images. BFA-YOLO incorporates three novel innovations: the Feature Balanced Spindle Module (FBSM) for addressing uneven distribution, the Target Dynamic Alignment Task Detection Head (TDATH) aimed at improving small object detection, and the Position Memory Enhanced Self-Attention Mechanism (PMESA) to combat background interference, with each component specifically designed to solve its corresponding challenge. Detection efficacy of deep network models deeply depends on the dataset's characteristics. Existing open source datasets related to building facades are limited by their single perspective, small image pool, and incomplete category coverage. We propose a novel method for building facade attachments detection dataset construction and construct the BFA-3D dataset for facade attachments detection. The BFA-3D dataset features multi-view, accurate labels, diverse categories, and detailed classification. BFA-YOLO surpasses YOLOv8 by 1.8% and 2.9% in mAP@0.5 on the multi-view BFA-3D and street-view Facade-WHU datasets, respectively. These results underscore BFA-YOLO's superior performance in detecting facade attachments.
LMFNet: An Efficient Multimodal Fusion Approach for Semantic Segmentation in High-Resolution Remote Sensing
Apr 21, 2024



Despite the rapid evolution of semantic segmentation for land cover classification in high-resolution remote sensing imagery, integrating multiple data modalities such as Digital Surface Model (DSM), RGB, and Near-infrared (NIR) remains a challenge. Current methods often process only two types of data, missing out on the rich information that additional modalities can provide. Addressing this gap, we propose a novel \textbf{L}ightweight \textbf{M}ultimodal data \textbf{F}usion \textbf{Net}work (LMFNet) to accomplish the tasks of fusion and semantic segmentation of multimodal remote sensing images. LMFNet uniquely accommodates various data types simultaneously, including RGB, NirRG, and DSM, through a weight-sharing, multi-branch vision transformer that minimizes parameter count while ensuring robust feature extraction. Our proposed multimodal fusion module integrates a \textit{Multimodal Feature Fusion Reconstruction Layer} and \textit{Multimodal Feature Self-Attention Fusion Layer}, which can reconstruct and fuse multimodal features. Extensive testing on public datasets such as US3D, ISPRS Potsdam, and ISPRS Vaihingen demonstrates the effectiveness of LMFNet. Specifically, it achieves a mean Intersection over Union ($mIoU$) of 85.09\% on the US3D dataset, marking a significant improvement over existing methods. Compared to unimodal approaches, LMFNet shows a 10\% enhancement in $mIoU$ with only a 0.5M increase in parameter count. Furthermore, against bimodal methods, our approach with trilateral inputs enhances $mIoU$ by 0.46 percentage points.