 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGD May Never Escape Saddle Points
Paper and Code
Jul 25, 2021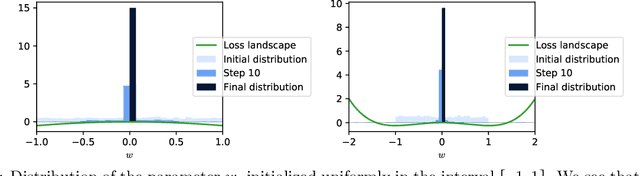
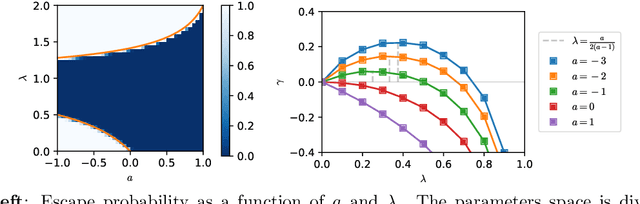


Stochastic gradient descent (SGD) has been deployed to solve highly non-linear and non-convex machine learning problems such as the training of deep neural networks. However, previous works on SGD often rely on highly restrictive and unrealistic assumptions about the nature of noise in SGD. In this work, we mathematically construct examples that defy previous understandings of SGD. For example, our constructions show that: (1) SGD may converge to a local maximum; (2) SGD may escape a saddle point arbitrarily slowly; (3) SGD may prefer sharp minima over the flat ones; and (4) AMSGrad may converge to a local maximum. Our result suggests that the noise structure of SGD might be more important than the loss landscape in neural network training and that future research should focus on deriving the actual noise structure in deep learning.