 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIt's My Data Too: Private ML for Datasets with Multi-User Training Examples
Paper and Code
Mar 05, 2025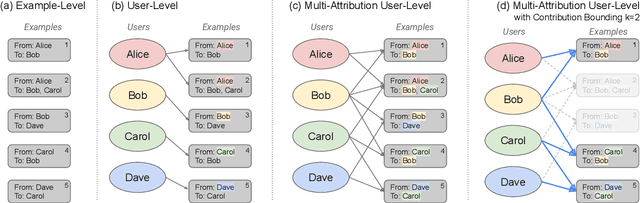
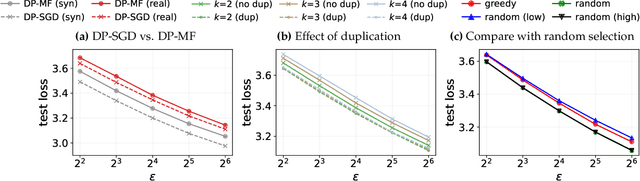
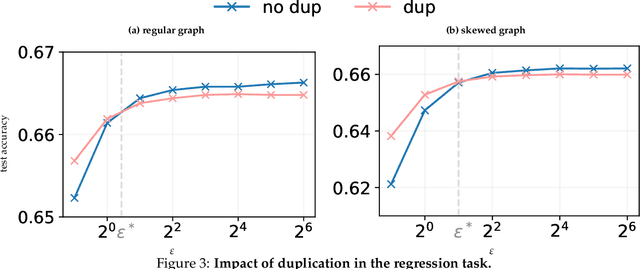
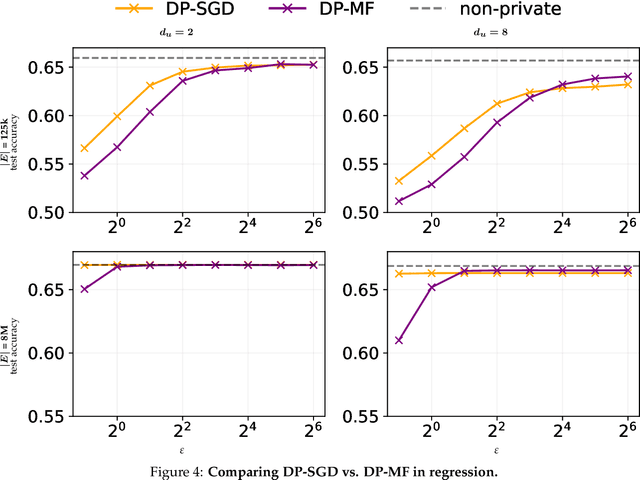
We initiate a study of algorithms for model training with user-level differential privacy (DP), where each example may be attributed to multiple users, which we call the multi-attribution model. We first provide a carefully chosen definition of user-level DP under the multi-attribution model. Training in the multi-attribution model is facilitated by solving the contribution bounding problem, i.e. the problem of selecting a subset of the dataset for which each user is associated with a limited number of examples. We propose a greedy baseline algorithm for the contribution bounding problem. We then empirically study this algorithm for a synthetic logistic regression task and a transformer training task, including studying variants of this baseline algorithm that optimize the subset chosen using different techniques and criteria. We find that the baseline algorithm remains competitive with its variants in most settings, and build a better understanding of the practical importance of a bias-variance tradeoff inherent in solutions to the contribution bounding problem.