 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Optimization:Distributed Optimization Beyond the Datacenter
Paper and Code
Nov 11, 2015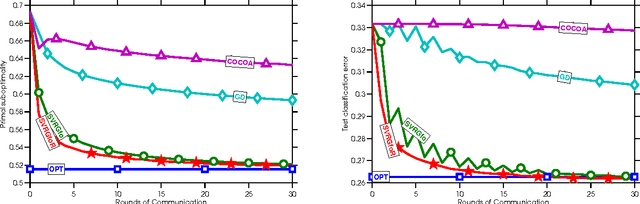
We introduce a new and increasingly relevant setting for distributed optimization in machine learning, where the data defining the optimization are distributed (unevenly) over an extremely large number of \nodes, but the goal remains to train a high-quality centralized model. We refer to this setting as Federated Optimization. In this setting, communication efficiency is of utmost importance. A motivating example for federated optimization arises when we keep the training data locally on users' mobile devices rather than logging it to a data center for training. Instead, the mobile devices are used as nodes performing computation on their local data in order to update a global model. We suppose that we have an extremely large number of devices in our network, each of which has only a tiny fraction of data available totally; in particular, we expect the number of data points available locally to be much smaller than the number of devices. Additionally, since different users generate data with different patterns, we assume that no device has a representative sample of the overall distribution. We show that existing algorithms are not suitable for this setting, and propose a new algorithm which shows encouraging experimental results. This work also sets a path for future research needed in the context of federated optimization.