 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee More, Store Less: Memory-Efficient Resolution for Video Moment Retrieval
Jan 14, 2026Recent advances in Multimodal Large Language Models (MLLMs) have improved image recognition and reasoning, but video-related tasks remain challenging due to memory constraints from dense frame processing. Existing Video Moment Retrieval (VMR) methodologies rely on sparse frame sampling, risking potential information loss, especially in lengthy videos. We propose SMORE (See MORE, store less), a framework that enhances memory efficiency while maintaining high information resolution. SMORE (1) uses query-guided captions to encode semantics aligned with user intent, (2) applies query-aware importance modulation to highlight relevant segments, and (3) adaptively compresses frames to preserve key content while reducing redundancy. This enables efficient video understanding without exceeding memory budgets. Experimental validation reveals that SMORE achieves state-of-the-art performance on QVHighlights, Charades-STA, and ActivityNet-Captions benchmarks.
GranAlign: Granularity-Aware Alignment Framework for Zero-Shot Video Moment Retrieval
Jan 02, 2026Zero-shot video moment retrieval (ZVMR) is the task of localizing a temporal moment within an untrimmed video using a natural language query without relying on task-specific training data. The primary challenge in this setting lies in the mismatch in semantic granularity between textual queries and visual content. Previous studies in ZVMR have attempted to achieve alignment by leveraging high-quality pre-trained knowledge that represents video and language in a joint space. However, these approaches failed to balance the semantic granularity between the pre-trained knowledge provided by each modality for a given scene. As a result, despite the high quality of each modality's representations, the mismatch in granularity led to inaccurate retrieval. In this paper, we propose a training-free framework, called Granularity-Aware Alignment (GranAlign), that bridges this gap between coarse and fine semantic representations. Our approach introduces two complementary techniques: granularity-based query rewriting to generate varied semantic granularities, and query-aware caption generation to embed query intent into video content. By pairing multi-level queries with both query-agnostic and query-aware captions, we effectively resolve semantic mismatches. As a result, our method sets a new state-of-the-art across all three major benchmarks (QVHighlights, Charades-STA, ActivityNet-Captions), with a notable 3.23% mAP@avg improvement on the challenging QVHighlights dataset.
Visual Funnel: Resolving Contextual Blindness in Multimodal Large Language Models
Dec 11, 2025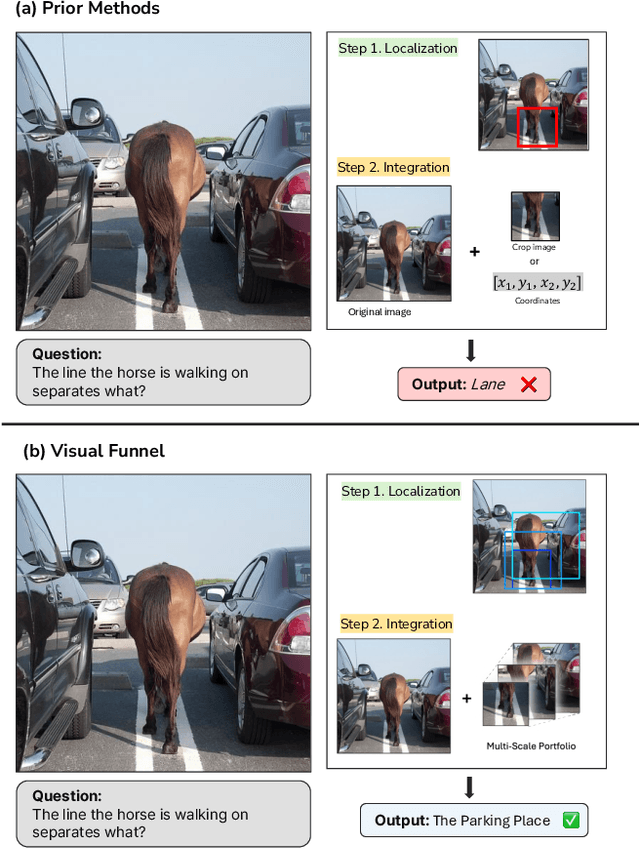
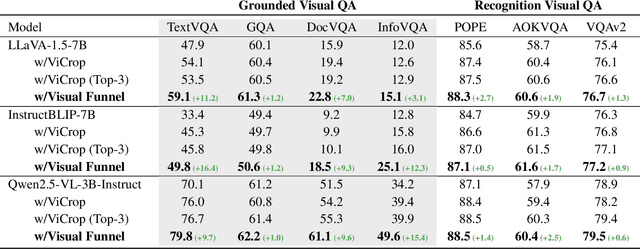
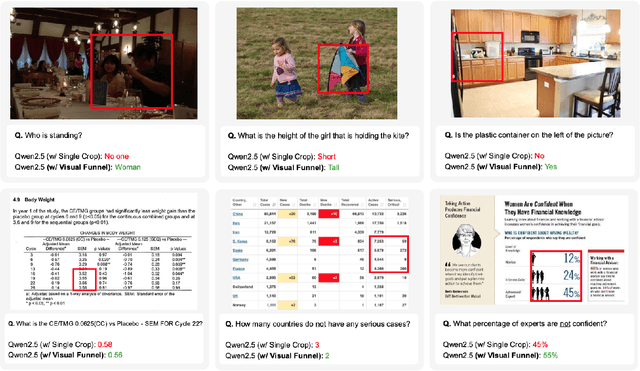
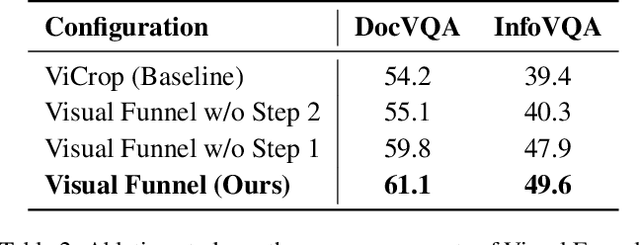
Multimodal Large Language Models (MLLMs) demonstrate impressive reasoning capabilities, but often fail to perceive fine-grained visual details, limiting their applicability in precision-demanding tasks. While methods that crop salient regions of an image offer a partial solution, we identify a critical limitation they introduce: "Contextual Blindness". This failure occurs due to structural disconnect between high-fidelity details (from the crop) and the broader global context (from the original image), even when all necessary visual information is present. We argue that this limitation stems not from a lack of information 'Quantity', but from a lack of 'Structural Diversity' in the model's input. To resolve this, we propose Visual Funnel, a training-free, two-step approach. Visual Funnel first performs Contextual Anchoring to identify the region of interest in a single forward pass. It then constructs an Entropy-Scaled Portfolio that preserves the hierarchical context - ranging from focal detail to broader surroundings - by dynamically determining crop sizes based on attention entropy and refining crop centers. Through extensive experiments, we demonstrate that Visual Funnel significantly outperforms naive single-crop and unstructured multi-crop baselines. Our results further validate that simply adding more unstructured crops provides limited or even detrimental benefits, confirming that the hierarchical structure of our portfolio is key to resolving Contextual Blindness.
Point to Span: Zero-Shot Moment Retrieval for Navigating Unseen Hour-Long Videos
Dec 11, 2025



Zero-shot Long Video Moment Retrieval (ZLVMR) is the task of identifying temporal segments in hour-long videos using a natural language query without task-specific training. The core technical challenge of LVMR stems from the computational infeasibility of processing entire lengthy videos in a single pass. This limitation has established a 'Search-then-Refine' approach, where candidates are rapidly narrowed down, and only those portions are analyzed, as the dominant paradigm for LVMR. However, existing approaches to this paradigm face severe limitations. Conventional supervised learning suffers from limited scalability and poor generalization, despite substantial resource consumption. Yet, existing zero-shot methods also fail, facing a dual challenge: (1) their heuristic strategies cause a 'search' phase candidate explosion, and (2) the 'refine' phase, which is vulnerable to semantic discrepancy, requires high-cost VLMs for verification, incurring significant computational overhead. We propose \textbf{P}oint-\textbf{to}-\textbf{S}pan (P2S), a novel training-free framework to overcome this challenge of inefficient 'search' and costly 'refine' phases. P2S overcomes these challenges with two key innovations: an 'Adaptive Span Generator' to prevent the search phase candidate explosion, and 'Query Decomposition' to refine candidates without relying on high-cost VLM verification. To our knowledge, P2S is the first zero-shot framework capable of temporal grounding in hour-long videos, outperforming supervised state-of-the-art methods by a significant margin (e.g., +3.7\% on R5@0.1 on MAD).
Color Information-Based Automated Mask Generation for Detecting Underwater Atypical Glare Areas
Feb 23, 2025Underwater diving assistance and safety support robots acquire real-time diver information through onboard underwater cameras. This study introduces a breath bubble detection algorithm that utilizes unsupervised K-means clustering, thereby addressing the high accuracy demands of deep learning models as well as the challenges associated with constructing supervised datasets. The proposed method fuses color data and relative spatial coordinates from underwater images, employs CLAHE to mitigate noise, and subsequently performs pixel clustering to isolate reflective regions. Experimental results demonstrate that the algorithm can effectively detect regions corresponding to breath bubbles in underwater images, and that the combined use of RGB, LAB, and HSV color spaces significantly enhances detection accuracy. Overall, this research establishes a foundation for monitoring diver conditions and identifying potential equipment malfunctions in underwater environments.