 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA self-supervised framework for learning whole slide representations
Feb 09, 2024
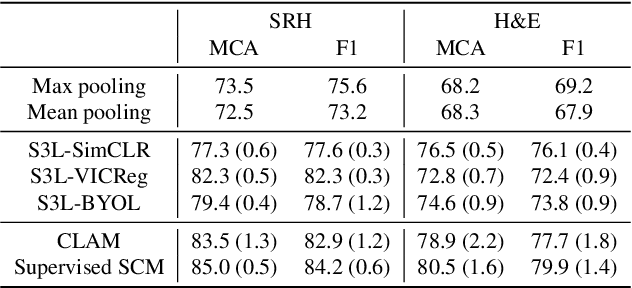
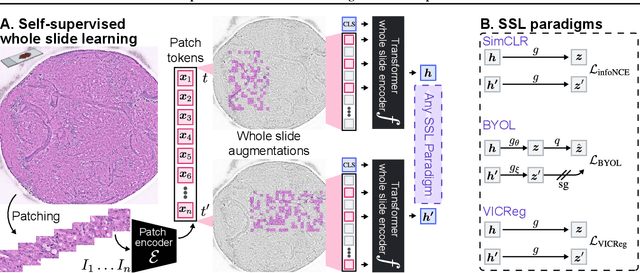
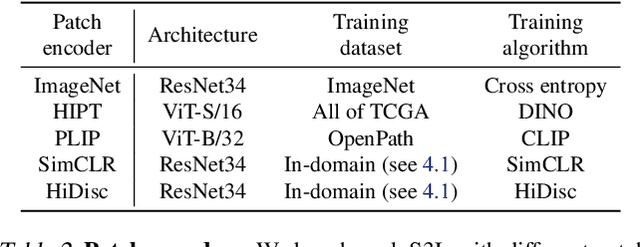
Whole slide imaging is fundamental to biomedical microscopy and computational pathology. However, whole slide images (WSIs) present a complex computer vision challenge due to their gigapixel size, diverse histopathologic features, spatial heterogeneity, and limited/absent data annotations. These challenges highlight that supervised training alone can result in suboptimal whole slide representations. Self-supervised representation learning can achieve high-quality WSI visual feature learning for downstream diagnostic tasks, such as cancer diagnosis or molecular genetic prediction. Here, we present a general self-supervised whole slide learning (S3L) framework for gigapixel-scale self-supervision of WSIs. S3L combines data transformation strategies from transformer-based vision and language modeling into a single unified framework to generate paired views for self-supervision. S3L leverages the inherent regional heterogeneity, histologic feature variability, and information redundancy within WSIs to learn high-quality whole-slide representations. We benchmark S3L visual representations on two diagnostic tasks for two biomedical microscopy modalities. S3L significantly outperforms WSI baselines for cancer diagnosis and genetic mutation prediction. Additionally, S3L achieves good performance using both in-domain and out-of-distribution patch encoders, demonstrating good flexibility and generalizability.