 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Sparse-Reward Object-Interaction Tasks in First-person Simulated 3D Environments
Paper and Code

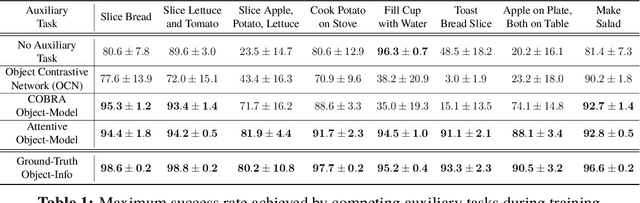
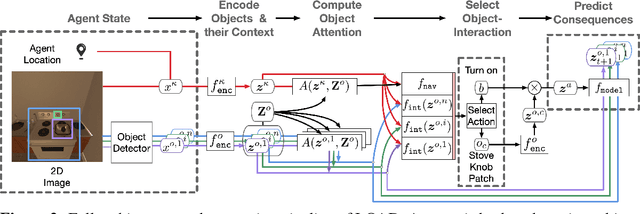
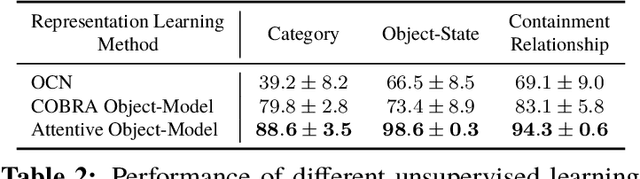
First-person object-interaction tasks in high-fidelity, 3D, simulated environments such as the AI2Thor virtual home-environment pose significant sample-efficiency challenges for reinforcement learning (RL) agents learning from sparse task rewards. To alleviate these challenges, prior work has provided extensive supervision via a combination of reward-shaping, ground-truth object-information, and expert demonstrations. In this work, we show that one can learn object-interaction tasks from scratch without supervision by learning an attentive object-model as an auxiliary task during task learning with an object-centric relational RL agent. Our key insight is that learning an object-model that incorporates object-attention into forward prediction provides a dense learning signal for unsupervised representation learning of both objects and their relationships. This, in turn, enables faster policy learning for an object-centric relational RL agent. We demonstrate our agent by introducing a set of challenging object-interaction tasks in the AI2Thor environment where learning with our attentive object-model is key to strong performance. Specifically, we compare our agent and relational RL agents with alternative auxiliary tasks to a relational RL agent equipped with ground-truth object-information, and show that learning with our object-model best closes the performance gap in terms of both learning speed and maximum success rate. Additionally, we find that incorporating object-attention into an object-model's forward predictions is key to learning representations which capture object-category and object-state.