 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Domain-Specific Word Embeddings from Sparse Cybersecurity Texts
Sep 21, 2017

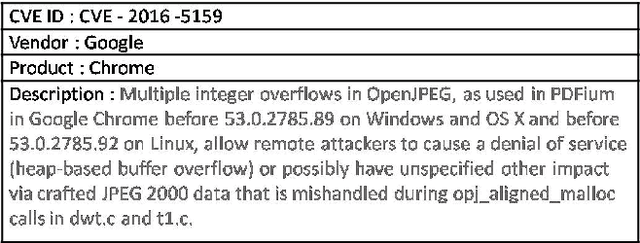
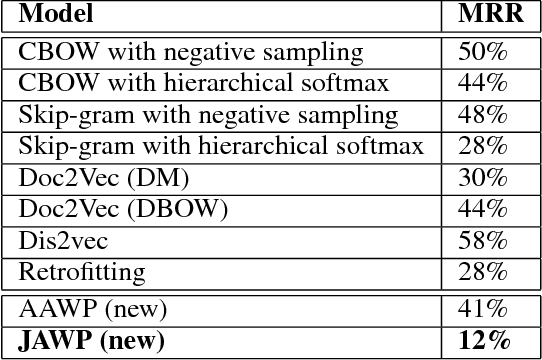
Word embedding is a Natural Language Processing (NLP) technique that automatically maps words from a vocabulary to vectors of real numbers in an embedding space. It has been widely used in recent years to boost the performance of a vari-ety of NLP tasks such as Named Entity Recognition, Syntac-tic Parsing and Sentiment Analysis. Classic word embedding methods such as Word2Vec and GloVe work well when they are given a large text corpus. When the input texts are sparse as in many specialized domains (e.g., cybersecurity), these methods often fail to produce high-quality vectors. In this pa-per, we describe a novel method to train domain-specificword embeddings from sparse texts. In addition to domain texts, our method also leverages diverse types of domain knowledge such as domain vocabulary and semantic relations. Specifi-cally, we first propose a general framework to encode diverse types of domain knowledge as text annotations. Then we de-velop a novel Word Annotation Embedding (WAE) algorithm to incorporate diverse types of text annotations in word em-bedding. We have evaluated our method on two cybersecurity text corpora: a malware description corpus and a Common Vulnerability and Exposure (CVE) corpus. Our evaluation re-sults have demonstrated the effectiveness of our method in learning domain-specific word embeddings.