 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFilterGS: Traversal-Free Parallel Filtering and Adaptive Shrinking for Large-Scale LoD 3D Gaussian Splatting
Mar 25, 20263D Gaussian Splatting has revolutionized neural rendering with real-time performance. However, scaling this approach to large scenes using Level-of-Detail methods faces critical challenges: inefficient serial traversal consuming over 60\% of rendering time, and redundant Gaussian-tile pairs that incur unnecessary processing overhead. To address these limitations, we introduce FilterGS, featuring a parallel filtering mechanism with two complementary filters that select Gaussian elements efficiently without tree traversal. Additionally, we propose a novel GTC metric that quantifies the redundancy of Gaussian-tile key-value pairs. Based on this metric, we introduce a scene-adaptive Gaussian shrinking strategy that effectively reduces redundant pairs. Extensive experiments demonstrate that FilterGS achieves state-of-the-art rendering speeds while maintaining competitive visual quality across multiple large-scale datasets. Project page: https://github.com/xenon-w/FilterGS
FedLog: Personalized Federated Classification with Less Communication and More Flexibility
Jul 11, 2024



In federated learning (FL), the common paradigm that FedAvg proposes and most algorithms follow is that clients train local models with their private data, and the model parameters are shared for central aggregation, mostly averaging. In this paradigm, the communication cost is often a challenge, as modern massive neural networks can contain millions to billions parameters. We suggest that clients do not share model parameters but local data summaries, to decrease the cost of sharing. We develop a new algorithm FedLog with Bayesian inference, which shares only sufficient statistics of local data. FedLog transmits messages as small as the last layer of the original model. We conducted comprehensive experiments to show we outperform other FL algorithms that aim at decreasing the communication cost. To provide formal privacy guarantees, we further extend FedLog with differential privacy and show the trade-off between privacy budget and accuracy.
Federated Bayesian Neural Regression: A Scalable Global Federated Gaussian Process
Jun 13, 2022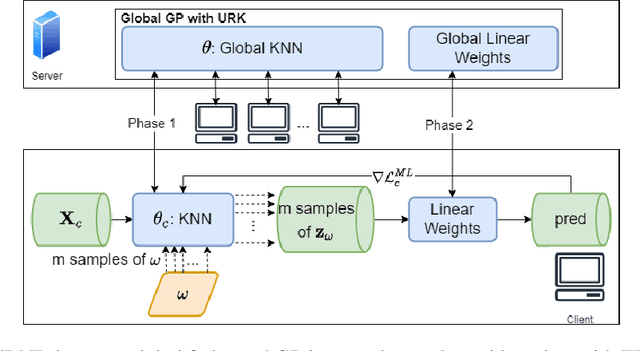
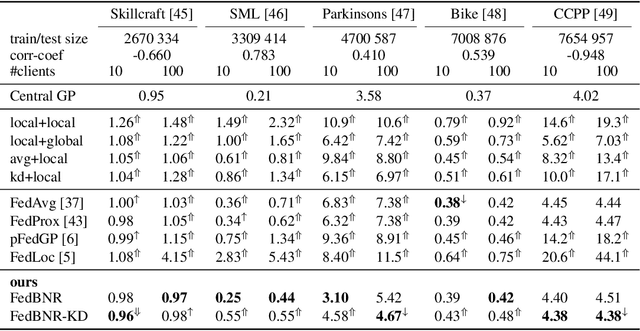
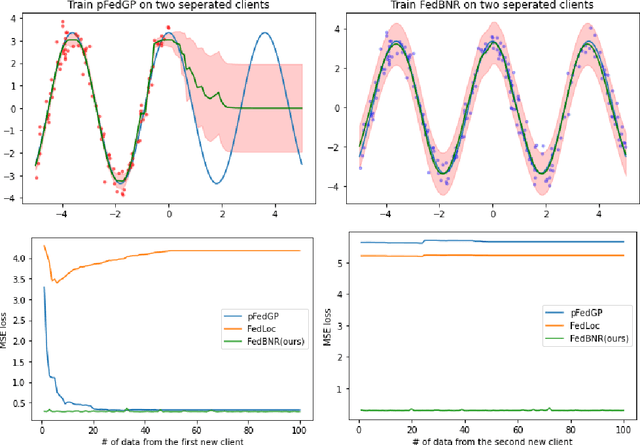
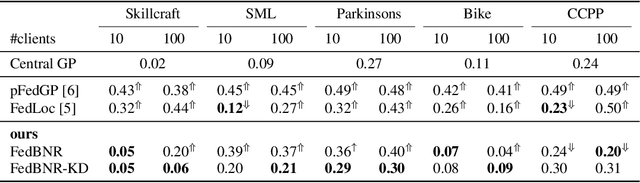
In typical scenarios where the Federated Learning (FL) framework applies, it is common for clients to have insufficient training data to produce an accurate model. Thus, models that provide not only point estimations, but also some notion of confidence are beneficial. Gaussian Process (GP) is a powerful Bayesian model that comes with naturally well-calibrated variance estimations. However, it is challenging to learn a stand-alone global GP since merging local kernels leads to privacy leakage. To preserve privacy, previous works that consider federated GPs avoid learning a global model by focusing on the personalized setting or learning an ensemble of local models. We present Federated Bayesian Neural Regression (FedBNR), an algorithm that learns a scalable stand-alone global federated GP that respects clients' privacy. We incorporate deep kernel learning and random features for scalability by defining a unifying random kernel. We show this random kernel can recover any stationary kernel and many non-stationary kernels. We then derive a principled approach of learning a global predictive model as if all client data is centralized. We also learn global kernels with knowledge distillation methods for non-identically and independently distributed (non-i.i.d.) clients. Experiments are conducted on real-world regression datasets and show statistically significant improvements compared to other federated GP models.