 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInduced Domain Adaptation
Paper and Code
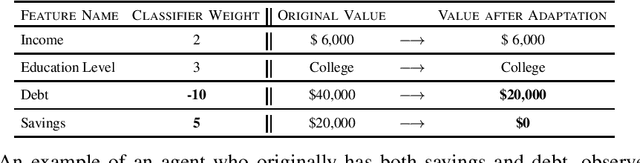
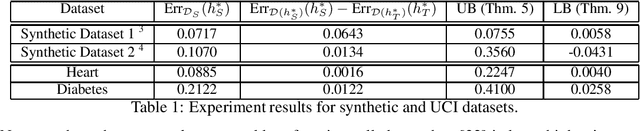
We formulate the problem of induced domain adaptation (IDA) when the underlying distribution/domain shift is introduced by the model being deployed. Our formulation is motivated by applications where the deployed machine learning models interact with human agents, and will ultimately face responsive and interactive data distributions. We formalize the discussions of the transferability of learning in our IDA setting by studying how the model trained on the available source distribution (data) would translate to the performance on the induced domain. We provide both upper bounds for the performance gap due to the induced domain shift, as well as lower bound for the trade-offs a classifier has to suffer on either the source training distribution or the induced target distribution. We provide further instantiated analysis for two popular domain adaptation settings with covariate shift and label shift. We highlight some key properties of IDA, as well as computational and learning challenges.